안녕하세요! 뉴스레터 구독자 여러분. 데이터Hub팀 데이터 사이언티스트 문기범입니다. Data@KU 뉴스레터 기사의 트래픽을 살펴보니, 구독자 여러분께서 네트워크 분석에 관심이 많으시더군요! 그런데 여러분, 네트워크가 인공지능 연구에서도 중요한 역할을 한다는 사실 알고 계셨나요? 네트워크 구조를 활용한 Graph Neural Network는 추천 알고리즘, 최적화, 컴퓨터 비전(Computer Vision), 물리학/화학 구조 분석 등 다양한 인공지능 기술에 널리 활용되고 있습니다 (참고: Top Applications of Graph Neural Networks 2021). 오늘은 네트워크 분석과 관련된 그래프 데이터베이스와 그 툴(tool)인 Neo4j에 대해 소개해 드리겠습니다.
- 그래프(graph)는 점(nodes, vertices)과 선(link, edge)으로 이루어진 구조를 의미하며, 학계에서는 네트워크라는 용어와 동의어처럼 사용됩니다. 그래프와 네트워크 용어에 대해 더 자세히 알고 싶으신 분은 다음 글을 참고해주세요! Graphs and networks
이번 기사를 통해 그래프 데이터베이스가 무엇이며 왜 필요한지, 그리고 그래프 데이터를 저장하고 활용할 수 있는 툴인 Neo4j를 어떻게 활용할 수 있는지 소개해 드리겠습니다! 기사의 후반부에서는 추천 알고리즘의 기초에 해당하는 콘텐츠 기반 필터링과 협업 필터링의 작동 방식도 간략하게 소개해드리겠습니다. 마지막으로 Neo4j를 활용해 콘텐츠 기반 필터링을 구현하는 과정을 함께 진행해보겠습니다!
기사의 구성은 아래와 같습니다.
1. 그래프 데이터베이스란?
2. 그래프 데이터베이스 Neo4j 소개 및 간단한 사용법
3. Neo4j를 사용한 추천모델 만들기(콘텐츠 기반 필터링 vs 협업 필터링)
그래프 데이터베이스란?
*그래프 데이터베이스에 대한 소개는 Neo4j 공식홈페이지와 Sudan님이 작성하신 WikiDocs 페이지(그래프 데이터베이스 (Neo4j)를 참고해 작성했습니다. *
그래프 데이터베이스는 그래프 이론에 기반한 NoSQL 데이터베이스의 일종입니다. 열과 행을 가진 테이블 형태로 데이터를 저장하는 기존의 관계형 데이터베이스(RDBMS)와 달리 그래프 데이터베이스는 노드와 노드들 사이의 링크를 저장합니다.
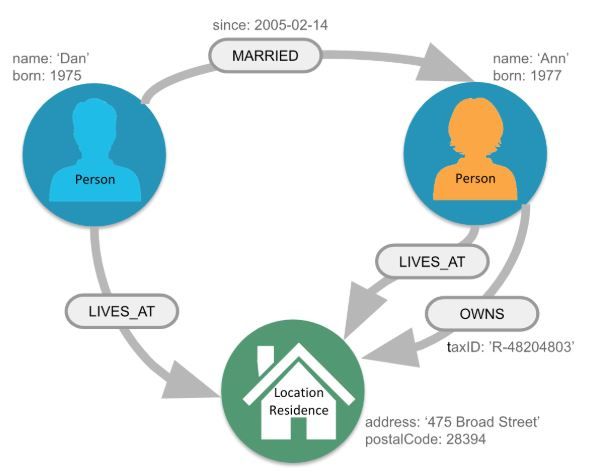
Neo4j와 같은 그래프 데이터베이스에서는 라벨을 사용해 노드의 유형을 정의할 수 있습니다. 하나의 노드에 여러 개의 라벨이 붙을 수 있습니다. 노드를 사용해 라벨을 검색할 수 있습니다. 링크는 노드와 노드가 어떻게 연결되어 있는지 나타냅니다. 출발 노드와 도착 노드가 정해져 있는 링크를 방향적 링크(directed link)라 하며 방향성이 없는 링크를 비방향적 링크(undirected link)라 합니다. 아래 그림에서 Person라벨이 붙은 노드는 Location Residence라벨이 붙은 노드와 LIVES_AT이라는 관계로 연결되어 있는 것을 확인할 수 있습니다. 노드와 링크에 속성을 추가하면 그래프 모델에 많은 정보를 담을 수 있습니다. 예를 들어 사용자 노드는 이름이라는 속성을 가질 수 있으며, 위치 노드는 주소라는 속성을 가질 수 있습니다. 또, MARRIED라는 링크를 통해 한 사용자 노드가 배우자 노드의 재산을 갖게 만들 수 있습니다.
참고: 비디오
데이터베이스에서 일반적으로 활용되는 관계형 모델과 지금 다루고 있는 그래프 모델 사이에는 유사점과 차이점이 모두 존재합니다. RDBMS의 테이블, 행, 열과 데이터, 조인(join)은 그래프 모델의 레이블(label), 노드, 속성과 값, 순회(traversal)에 대응합니다. 관계형 모델은 자주 바뀌지 않는 데이터를 저장기에는 적합하지만, 다이나믹하게 바뀌는 데이터를 처리하거나 서로 다른 데이터를 연결(join)한 분석을 수행하기에는 많이 무거운 편입니다. 그래서 관계형 데이터베이스는 데이터를 안정적으로 저장하는 데 적합하고, 그래프 모델은 다양한 데이터를 연결해 그 속에서 인사이트를 찾아내는 데 더 적합할 수 있습니다.
그래프 데이터베이스의 필요성
*아래 내용은 그래프 데이터베이스의 필요성과 사례에 대한 소개입니다. Neo4j 실습을 바로 진행하고 싶은 분들은 뛰어 넘어도 괜찮습니다. *
이번에는 제가 그래프 데이터베이스에 관심을 갖게 된 이유를 말씀드리겠습니다. 소셜 네트워크 분석은 저희 데이터 사이언티스트들이 교내 데이터를 분석할 때 가장 많이 활용하게 되는 방법 중 하나입니다. "소셜(social)"이라는 명칭에서 나타나듯 소셜 네트워크 분석은 인간과 인간의 관계를 분석하는 목적으로 널리 활용되고 있습니다. 예를 들어 Data@KU 3월호: 이번 학기 내 친구가 될 수 있는 사람들은 누구일까?에서 이진숙 선생님은 수간신청 데이터와 Louvain Community Detection 알고리즘을 활용해 수강신청 패턴이 유사한 학생 커뮤니티를 식별하는 분석을 소개해 주었습니다.
하지만 소셜 네트워크 분석을 가지고 인간관계에 관한 분석만 할 수 있는 것은 아닙니다. 사실상 "관계"의 특성을 밝히는 것이 분석의 목적이라면, 거의 모든 분석에 소셜 네트워크 분석 기법을 활용할 수 있습니다. 예를 들어, Data@KU 2월호: 고려대학교 대학원의 다양성 두 번째 이야기에서 김진원 선생님은 네트워크 분석을 통해 대학원 신입생의 소속학과와 대학원 전공학과 사이의 관계를 분석했습니다. 이와 유사하게 Data@KU 3월호: Scival을 통해 알아본 고려대학교 사회과학 연구 현황에서 최하림 선생님은 연구논문 키워드 데이터를 활용해 각 키워드 사이의 관계가 어떤지 살펴보고 키워드들의 클러스터를 구분하였습니다.
일반적으로 데이터 사이언티스트가 소셜 네트워크 분석을 하는 과정은 다음과 같습니다. 먼저, 분석 주제별로 필요한 데이터를 앞서 소개해드린 관계형 데이터베이스에서 추출합니다. 교내 관계형 데이터베이스의 주목적은 시스템의 안정적인 운영이기 때문에 데이터베이스의 구조가 분석에 최적화되어 있지 않은 경우가 많습니다. 이런 경우 데이터 사이언티스트들은 데이터베이스 내에 존재하는 여러 테이블에서 필요한 데이터를 추출해 병합합니다. 이렇게 데이터 세트가 갖추어지면, 분석 목적에 맞게 노드와 엣지(링크)를 정의합니다. 사실 실질적인 분석 자체보다 이렇게 소셜 네트워크 분석을 하기 위한 데이터 세트 형태를 갖추는 데 더 많은 시간이 소요되곤 합니다.
만약 그래프 데이터 구조를 통해 소셜 네트워크 분석을 할 수 있는 데이터가 언제든지 준비되어 있다면 어떨까요? 이것이 바로 제가 그래프 데이터베이스를 구축할 수 있는 프레임워크인 Neo4j에 관심을 갖게 된 계기입니다 🙂 실제로 Airbnb 같은 기업 또한 비슷한 문제를 해결하기 위해 Neo4j를 도입했다고 합니다.
Airbnb는 회사의 급격한 성장과 조직의 시공간적 복잡성으로 인해 조직원간 원활한 소통이 어려워졌다고 합니다. 이에 더해 데이터 소스가 다양해지고 여러 2차 분석이 이루어지면서, 데이터를 통합적으로 관리하는 게 매우 힘들어졌습니다. Airbnb의 데이터팀은 회사 내 구성원들에게 필요한 데이터를 쉽게 찾기 어렵다는 핀잔을 들어야 했습니다. 이런 문제를 해결하기 위해 Airbnbn 데이터팀은 Neo4j를 도입하게 되었습니다. 이들은 회사 데이터 리소스가 각각 여러 레벨 특성 수준의 문맥과 연결을 가지고 있기 때문에, 그래프로 가장 잘 나타낼 수 있을 것이라고 판단했습니다. Neo4j로 데이터 베이스를 구축하고 Python Flask로 API를 구성했으며, React와 Redux로 이를 서비스하는 웹 페이지를 제작했다고 합니다. 여기서 나아가 graph topology의 장점을 활용해 데이터 검색의 정확도를 개선했습니다. 매일 Airbnb에서 생산되는 Hive 내 모든 데이터가 Neo4j grpah database에 축적되며, 빠르고 정확한 데이터 검색이 가능해졌다고 합니다.
서론이 너무 길었죠? 그럼 바로 Neo4j를 만나로 떠나보겠습니다!
Neo4j 시작하기
그럼 지금부터 Neo4j 실습을 진행해보겠습니다! Neo4j를 직접 PC에 설치할 수도 있지만, 간단한 실습을 위해 위 네모칸 속 Sanbox 모드를 선택해보겠습니다. Sandbox 모드에서는 임시 프로젝트를 만들어 Neo4j를 자유롭게 연습할 수 있습니다.
위 네모칸 속 Open 버튼을 클릭하면 헐리우드 영화 데이터를 활용한 실습이 진행됩니다.
우리말 안내가 없어서 당황하셨나요? 이럴 땐 크롬 브라우저에 내장된 한국어 번역 기능을 사용하시면 됩니다. 브라우저 창에서 마우스 오른쪽 버튼을 클릭한 후, 아래 캡처 화면처럼 "한국어(으)로 번역"을 클릭하면 한국어로 번역된 튜토리얼을 진행할 수 있습니다. 요즘 인공지능 번역기 매우 훌륭하기 때문에 영어 울렁증이 있으신 분들에게 강추하는 방법입니다!
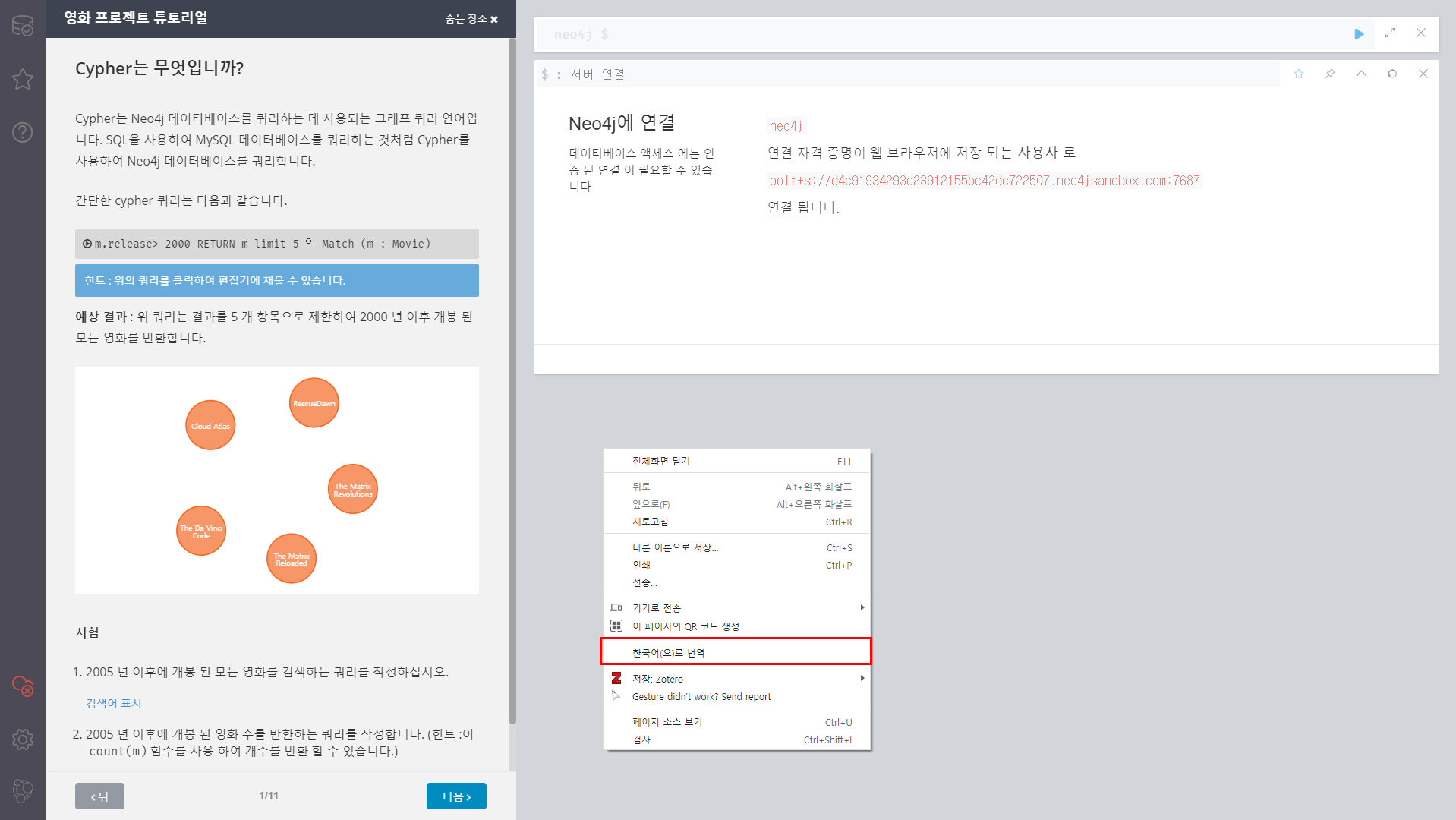
Sandbox가 실행되면 웹 브라우저에 위와 같은 페이지가 표시됩니다. 왼쪽 창에 Cypher를 사용해 Neo4j 데이터베이스에서 데이터를 조회하고 가공하는 방법이 친절하게 안내되어 있습니다. Cypher는 캡쳐 화면에 설명되어 있는 대로, Neo4j 데이터베이스를 조회하는 데 사용하는 언어입니다. SQL의 Neo4j 버전이라고 생각하시면 됩니다. 한 단계, 한 단계 진행하다보면 Neo4j와 Cypher 쿼리의 특징을 파악할 수 있습니다.
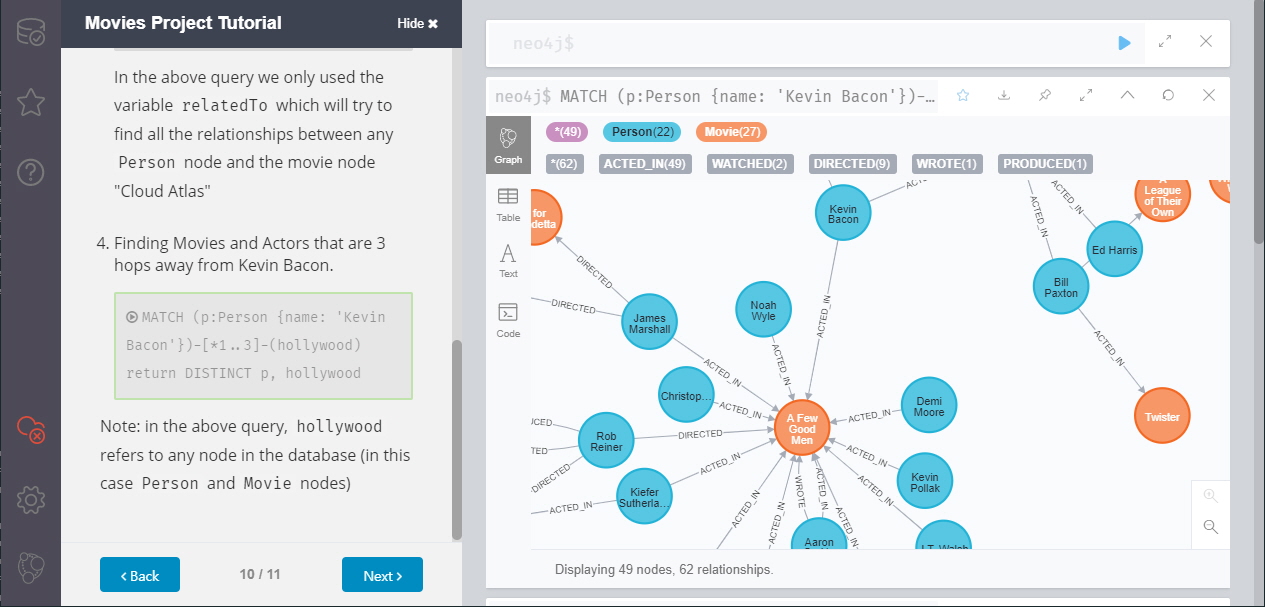
제가 Neo4j에서 가장 신선했던 점 중에 하나는 쿼리문의 결과가 바로 네트워크 플롯으로 출력된다는 점입니다. 쿼리 질의 결과는 JSON이나 CSV 파일로 다운로드 받을 수 있습니다. 그리고 네트워크 플롯 또한 PNG 파일이나 SVG 파일로 다운로드 받을 수 있었습니다. 노드와 링크의 수가 매우 많은 경우에는 쿼리질의 결과를 내보내기 한 후 이전에 소개드린 Gephi 프로그램을 사용해 시각화 하는 것을 추천드립니다.
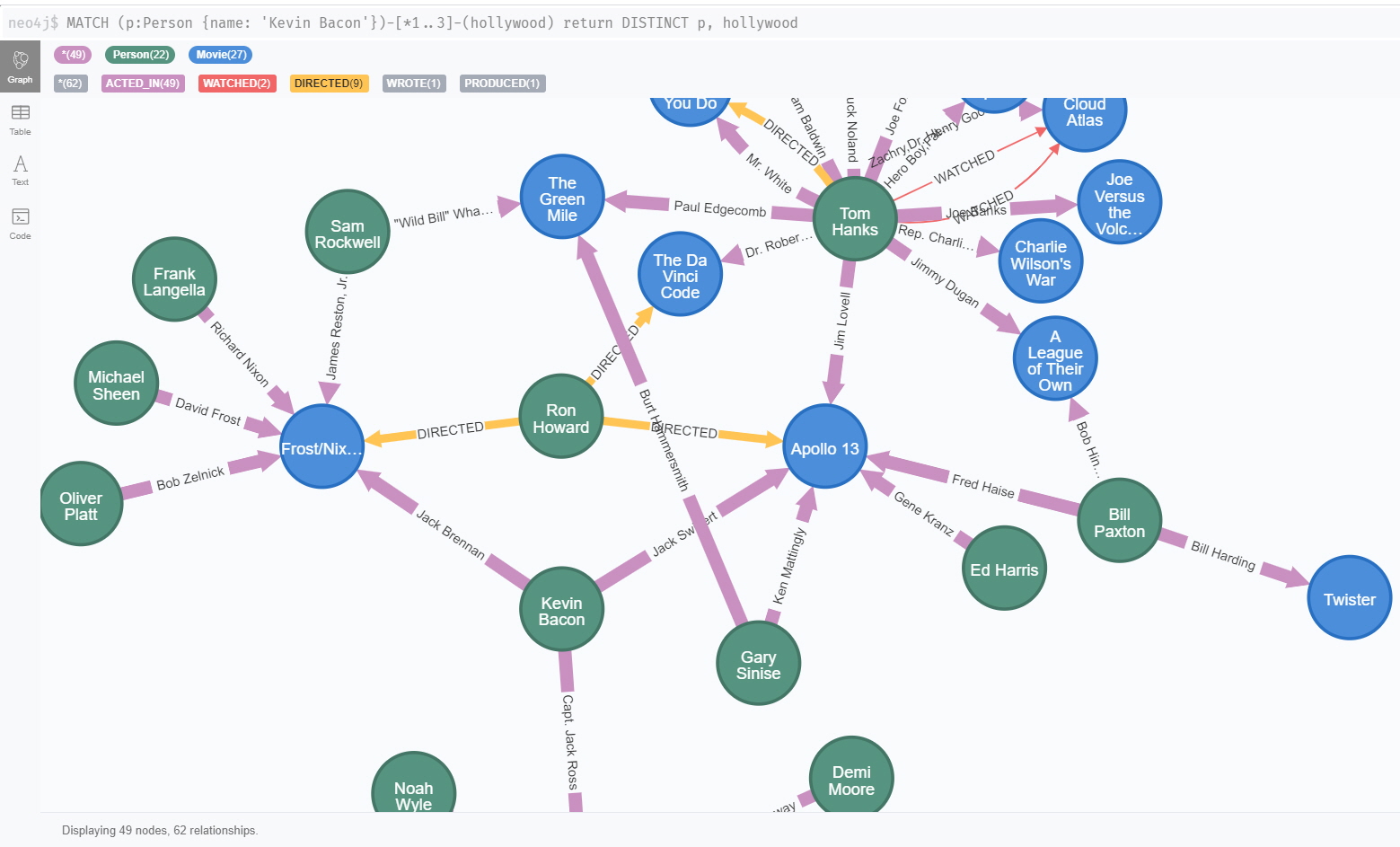
(쿼리 결과로 그려진 플롯의 노드와 링크의 크기와 색, 표시되는 라벨 등을 자유롭게 수정할 수 있었습니다.)
심화 예제
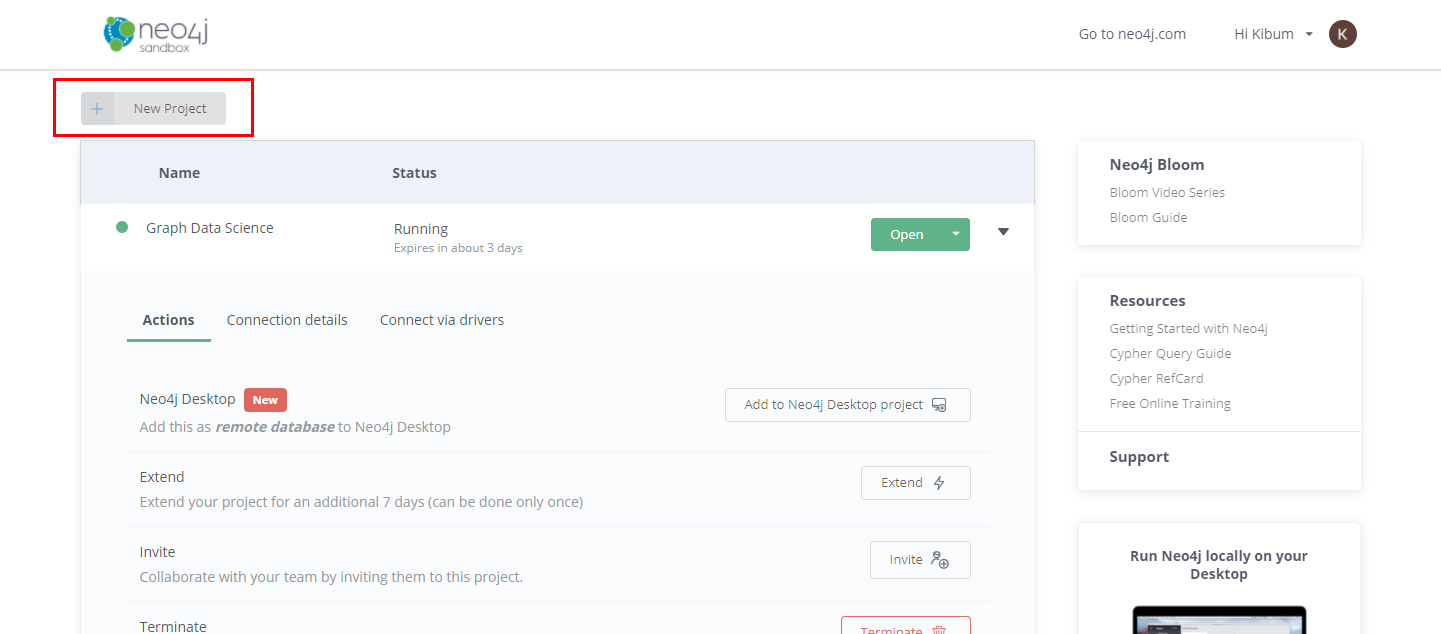
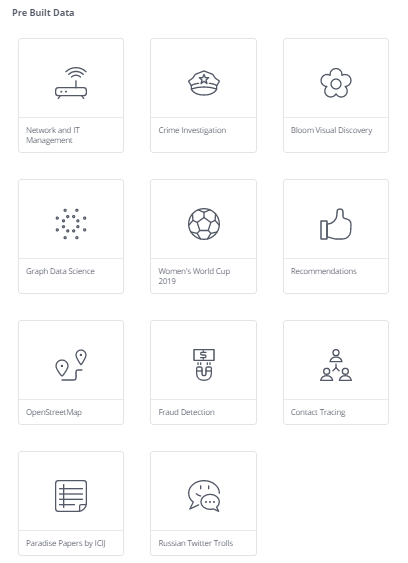
Movie 예제를 끝까지 잘 해보셨나요? 위 New Project를 클릭하면 11개의 심화 예제를 추가로 공부할 수 있습니다. 심화 예제 목록은 아래 이미지에 표시되어 있습니다. 저는 앞서 말씀드린 대로 Recommendations 예제를 진행해보겠습니다. 이 외에도 Crime Investigation이나 Graph Data Science이 흥미로워 보입니다. Graph Data Science에서는 Cypher를 사용해서 중심성과 유사도 점수를 계산하는 방법이나, 커뮤니티 탐색하는 방법에 대해 살펴본다고 합니다.
Neo4j를 사용한 추천모델 만들기
그럼 이번에는 Neo4j를 활용한 영화추천 모델을 함께 만들어 보겠습니다.
그래프 데이터베이스 기반 영화추천 모델
Recommendation 예제의 첫 화면입니다. 이번 예제에서는 앞서 소개한 영화 데이터를 가지고 개인화된 영화 추천 알고리즘을 제작하는 과정을 배우게 됩니다. 그래프 기반 추천 모델은 실시간 추천이 가능하고 서로 떨어져 있는 데이터를 연결할 수 있다는 장점이 있다고 합니다.
영화 그래프 데이터 모델
영화 그래프 데이터를 함께 살펴볼까요? 가장 먼저 노드(nodes), 관계(relationships), 특성(properties)이 눈에 들어옵니다.
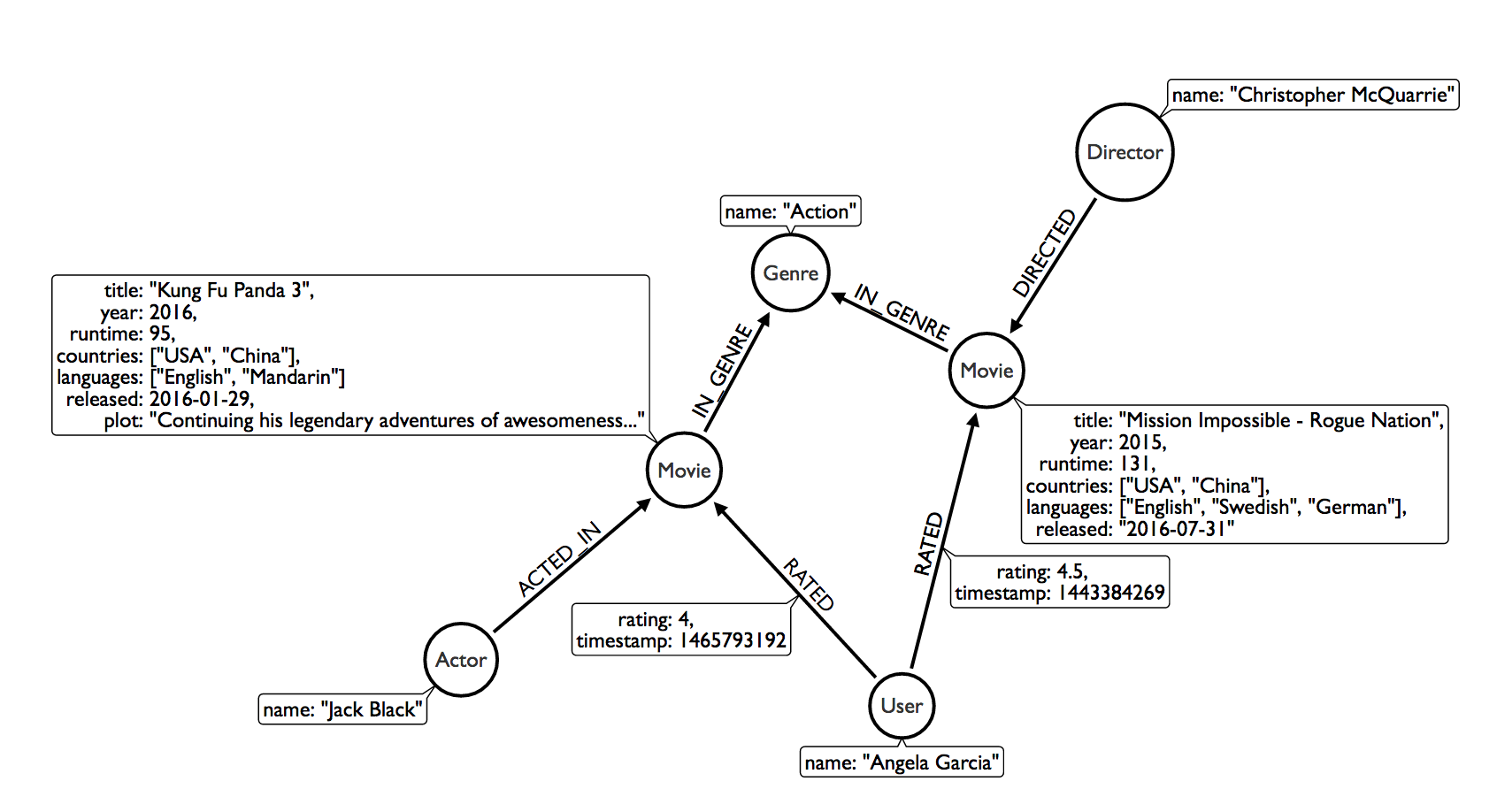
노드
위 그림 속에서 노드는 원으로 표현되어 있네요. 각 노드는 Move, Actor, Director, User, Genre라는 라벨(label)을 가지고 있습니다. 영화 그래프 데이터에서는 사람과 영화과 노드가 되네요. 처음에 살펴보았듯, 하나의 노드는 여러 개의 라벨을 가지고 있을 수 있습니다. 예를 들어, 영화 배우겸 감동인 맬 깁슨 노드는 Actor 라벨과 Director 라벨을 모두 가질 수 있습니다.
관계
노드와 노드를 연결하는 선, 즉 엣지(edge) 또는 링크(link)는 노드와 노드 사이의 관계를 나타냅니다. 영화 데이터에서 관계는 ACTED_IN , IN_GENRE, DIRECTED, RATED가 있습니다.
특성
특성 요소를 통해 노드와 관계에 대한 추가적인 정보를 표시할 수 있습니다. 이 예제에는 title, name, year, rating 등의 특성 요소가 있습니다. 위 세 가지 요소를 종합해, "잭 블랙(Jack Black)" 배우가 2016년 개봉한 "쿵푸 팬더3"에 출현했고, "안젤라 가르시아(Angela Garcia)"라는 사용자가 이 영화에 4점을 주었다는 사실 등을 읽어낼 수 있습니다.
Cypher 해부하기
본격적으로 추천 모델을 만들기 전에 그래프 데이터베이스의 쿼리 문법인 Cypher를 다시 한 번 살펴보겠습니다. 예제에서는 "매트릭스 각 시리즈별 평개 갯수"를 확인하는 쿼리로 Cypher를 연습합니다.
xxxxxxxxxxMATCH (m:Movie)<-[:RATED]-(u:User)WHERE m.title CONTAINS "Matrix"WITH m.title AS movie, COUNT(*) AS reviewsRETURN movie, reviewsORDER BY reviews DESC
위 Cypher 쿼리문의 의미를 분해해보겠습니다.
(1) 사용자(User)가 영화(Movie)를 평가(Rated)한 관계를 찾아라 (2) 그 중에서 영화 이름(m.title)이 "Matrix"인 것을 필터링해라 (3) 영화 이름(m.title)으로 movie열을 생성하고, 각 영화별 행의 갯수를 세서 reviews열에 넣어라. (4) movie열과 reviews열을 출력해라 (5) reviews 수를 기준으로 내림차순 정리해라
2가지 추천 모델
이제 드디어 추천 모델을 만드는 단계입니다! 추천 모델에는 여러 종류가 있지만, 이번 예제에서는 콘텐츠 기반 필터링(Content-based filtering)과 협업 필터링(Collaborative filtering)을 소개하고 있습니다. 하나씩 차례로 알아보겠습니다.
콘텐츠 기반 필터링
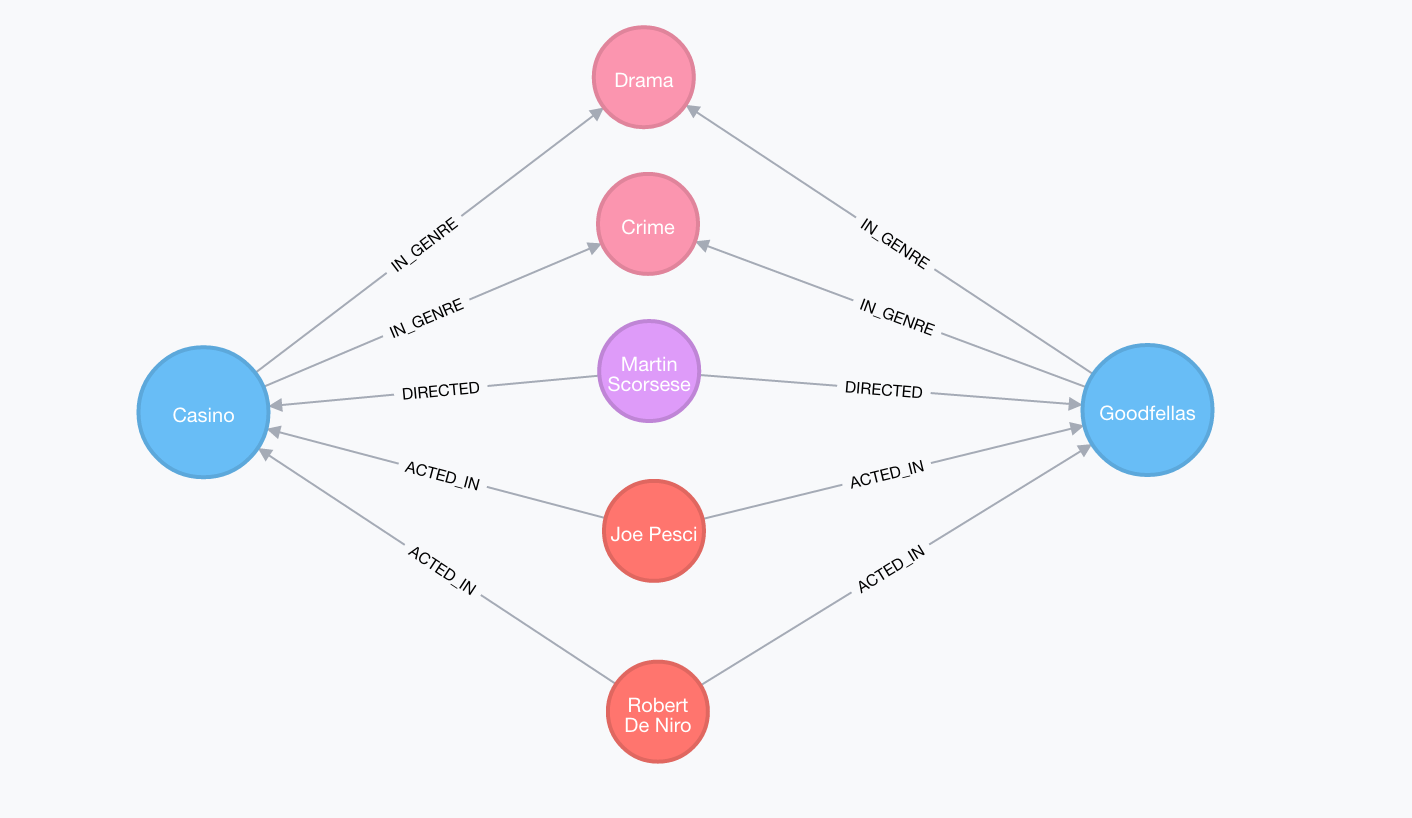
콘텐츠 기반 필터링의 원리는 매우 간단합니다. 어떤 사용자가 높은 평점을 준 영화와 가장 유사한 영화를 추천해주는 것입니다. 예를 들어, 아래 제시된 두 영화 "카지노(Casino)"와 "좋은 친구들(GoodFellas)"는 영화 장르, 감독, 주연 배우들이 모두 같은 매우 유사한 영화입니다. 카지노를 재미있게 본 사용자에게 이와 매우 유사한 "좋은 친구들"을 추천해주는 방식입니다. 이 추천방식은 어떤 영화에 높은 평점을 준 사용자는 이와 유사한 영화를 좋아할 것이라는 가정을 가지고 있습니다. 아래 그림에서처럼 영화 장르, 감독, 배우 등이 영화들 사이의 유사도를 계산하는 기준이 될 수 있습니다.
협업 필터링
협업 필터링은 추천 영화를 선정하기 위해 네트워크 내 다른 사용자의 평가 점수를 활용하는 방식입니다. 일반적으로 협업 필터링은 두 단계로 진행됩니다. 먼저 기존 영화 평점 데이터를 활용해 한 사용자와 영화 취향이 가장 유사한 사람들을 식별합니다. 그런 다음, 이 사람들이 평균적으로 높은 평점을 준 영화를 해당 사용자에게 추천해줍니다. "AI 선배: 교양과목 추천서비스 - 학우기반 추천" 또한 협업 필터링 방법을 사용하고 있습니다.
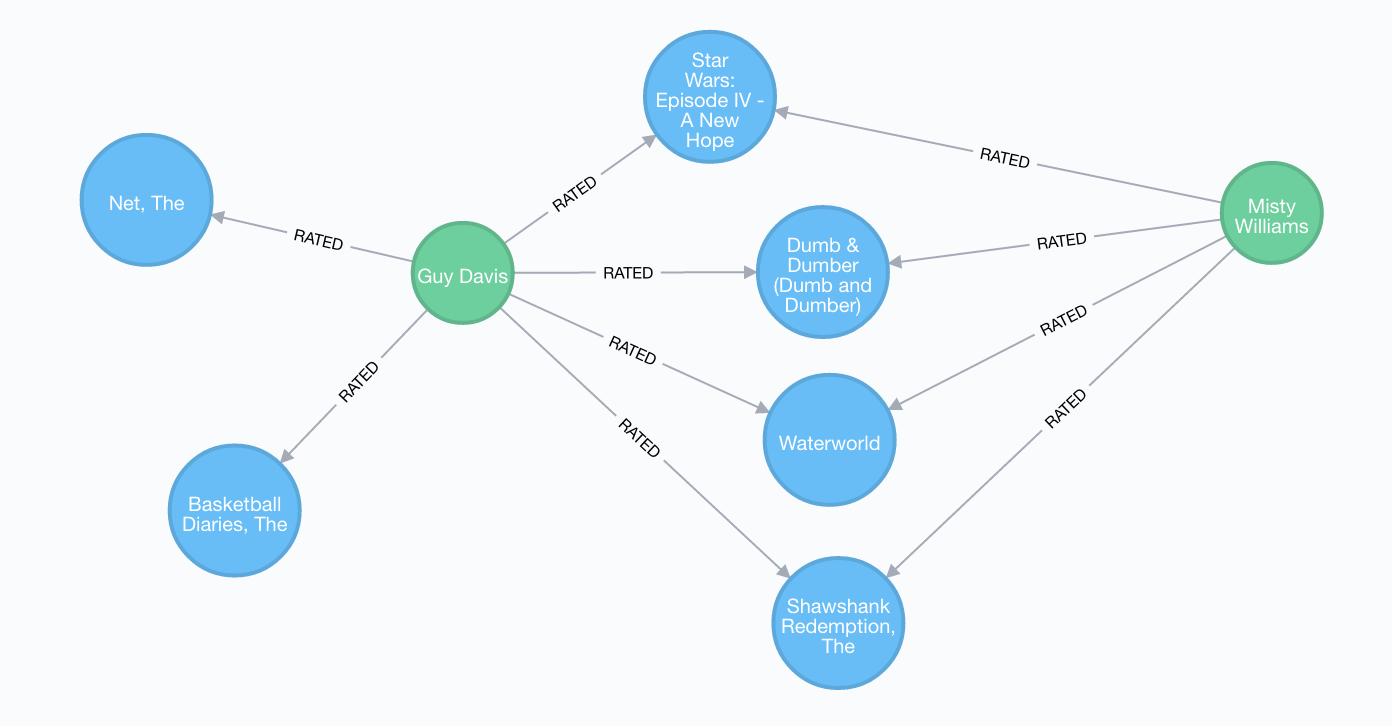
Cypher 기반 추천 모델1: 콘텐츠 기반 필터링
그럼 이제 정말 추천 모델을 만드는 단계입니다! 함께 콘텐츠 기반 필터링을 사용한 추천 모델을 작성하는 예제를 진행하시죠! 영화의 장르(Genre)를 기준으로 가장 유사한 영화를 추천해주는 모델을 제작하는 과정입니다.
인셉션(Inception)과 유사 장르 영화 탐색
과연 "인셉션(Inception)"과 가장 유사한 장르의 영화는 무엇일까요? 아래는 방금 문제의 답을 알려주는 Cypher 쿼리문입니다.
xxxxxxxxxxMATCH (m:Movie)-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(rec:Movie)WHERE m.title = "Inception"WITH rec, COLLECT(g.name) AS genres, COUNT(*) AS commonGenresRETURN rec.title, genres, commonGenresORDER BY commonGenres DESC LIMIT 10;
Cypher 코드를 하나하나 살펴보겠습니다. 첫 번째 단계 MATCH절에서는 어떤 영화(m:Movie)와 같은 장르(Genre)를 갖고 있는 추천 영화(rec:Movie)를 필터링 합니다. 이때 where m.title = "Inception"은 인셉션("Inception")을 기준으로 필터링을 하라는 의미입니다.
xxxxxxxxxxMATCH (m:Movie)-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(rec:Movie)WHERE m.title = "Inception"
다음 단계는 이렇게 필터링된 결과를 출력하는 방식을 결정하는 과정입니다. WITH절에서 재료를 골라 RETURN절에서 접시에 담는다고 생각하면 이해하기 쉬울 것 같습니다 🙂 WITH절에서 인셉션과 각 추천 영화(rec)가 공통으로 가지고 있는 장르 요소의 이름(g.name)을 genres라고 저장하고, 그 갯수를 commonGenres로 저장합니다. 여기서 노드를 g로 그 특성을 . + name으로 하는 것을 눈여겨 봐주세요. RETURN절은 쿼리 결과의 출력을 결정하는 부분입니다. rec.title로 추천 영화의 제목을 가지고 오고, 앞선 WITH절에서 생성한 공통 장르(genres)와 그 수(commonGenres)를 3개의 컬럼으로 하는 테이블이 출력됩니다.
xxxxxxxxxxWITH rec, COLLECT(g.name) AS genres, COUNT(*) AS commonGenresRETURN rec.title, genres, commonGenres
마지막 부분은 아주 간단합니다. ORDER BY를 보고 알 수 있듯 인셉션과 장르 요소가 겹치는 갯수 별로 추천 영화를 내림차순(DESC)으로 정렬하고 상위 10개(LIMIT 10)를 선택하라는 뜻입니다.
xxxxxxxxxxORDER BY commonGenres DESC LIMIT 10;
아래 캡처화면은 위에서 살펴본 쿼리 실행 결과입니다. 패트레이버, 스트레인지 데이즈, 와치맨 등이 인셉션과 유사한 장르를 갖고 있는 영화로 출력되었네요. 그럴 듯 한가요?
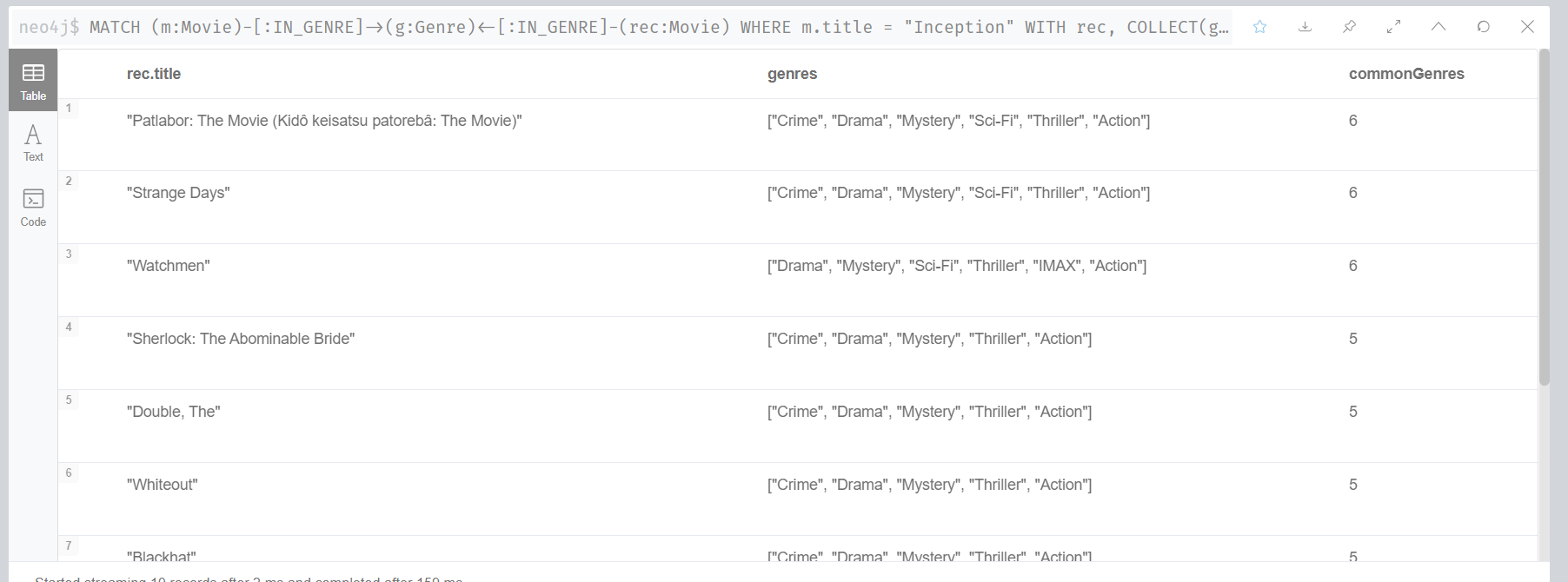
개인별 선호 장르 기반 추천
위에서는 인셉션이라는 특정 영화와 가장 유사한 영화를 탐색하는 과정이었습니다. 인셉션을 좋아하는 사람에게는 의미있는 정보겠지만, 인셉션을 좋아하지 않은 사람에게는 의미없는 정보일 수 있습니다. 만약 어떤 사람이 기존에 시청한 영화 목록을 알고 있다면, 이에 기반해 개인화된 추천 목록을 만들 수 있습니다. 이 과정을 함께 살펴보겠습니다.
xxxxxxxxxxMATCH (u:User)-[r:RATED]->(m:Movie), (m)-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(rec:Movie)WHERE u.name = "Angelica Rodriguez" and NOT EXISTS( (u)-[:RATED]->(rec) ) WITH rec, [g.name, COUNT(*)] AS scores RETURN rec.title AS recommendation, rec.year AS year, COLLECT(scores) AS scoreComponents,REDUCE (s=0,x in COLLECT(scores) | s+x[1]) AS score ORDER BY score DESC LIMIT 10
MATCH절부터 살펴보겠습니다. 이번에는 앞선 쿼리와 비교해 두 가지 요소가 추가되었습니다. 바로 사용자 노드(u:User)와 평가 링크(r:RATED)입니다. 영화에 대한 평가가 있으면 해당 영화를 보았다고 가정하는 것입니다.
WHERE의 u.name = "Angelica Rodriguez"는 여러 사용자 중에서 "Angelica Rodriguez"라는 사람의 데이터만을 사용한다는 것을 나타냅니다. NOT EXISTS( (u)-[:RATED]->(rec) ) 부분은 사용자가 추천 영화(rec)를 평가하는 연결은 존재하지 않는다고 설정하는 부분입니다. NOT EXISTS에 대해 더 살펴보고 싶은 분은 사용자_가이드를 참고해 주세요.
xMATCH (u:User)-[r:RATED]->(m:Movie), (m)-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(rec:Movie)WHERE u.name = "Angelica Rodriguez" and NOT EXISTS( (u)-[:RATED]->(rec) )
다음으로 추천 결과를 생성하는 부분입니다. WITH절에서 추천 영화 노드(rec)와 scores라는 값을 사용한다는 것을 알 수 있습니다. scores는 추천 영화의 장르가 Angelica Rodriguez가 지금까지 본 영화의 장르와 각 장르별(g.name)로 얼마나 겹치는지를 의미합니다. 즉 어떤 영화가 Adventure라는 이름의 장르 요소를 가지고 있고, Angelica Rodriguez가 본 Adventure영화가 5개라면 ["Adventure", 5]가 되는 것입니다.
xxxxxxxxxxWITH rec, [g.name, COUNT(*)] AS scores
이번 RETURN절은 조금 복잡해 보이니 찬찬히 살펴보겠습니다. rec.title AS recommendation은 말 그대로 추천영화 노드(rec)의 제목(title) 속성을 recommendation이라는 열에 넣으라는 말입니니다. rec.year AS year는 추천 영화의 개봉 연도를 year열에 넣으라는 말입니다. 그리고 COLLECT(scores) AS scoreComponents는 위 WITH절에서 생성한 scores를 scoreComponents 속에 전부 집어 넣으라는 말입니다. REDUCE (s=0,x in COLLECT(scores) | s+x[1]) AS score는 각 추천 영화별로 scores의 숫자를 모두 합해 score라는 열에 넣으라는 말입니다. 인셉션 때와 마찬가지로 score값을 기준으로 상위 10개 영화를 선택합니다. 복잡해 보여도 아래 출력 결과를 보시면 무슨 말인지 쉽게 이해하실 수 있을 것입니다.
xxxxxxxxxxRETURN rec.title AS recommendation, rec.year AS year, COLLECT(scores) AS scoreComponents,REDUCE (s=0,x in COLLECT(scores) | s+x[1]) AS score ORDER BY score DESC LIMIT 10
앞서 설명드린대로 scoreComponents에는 scores가 다 들어가 있고, score에는 합계 값이 저장된 것을 알 수 있습니다.
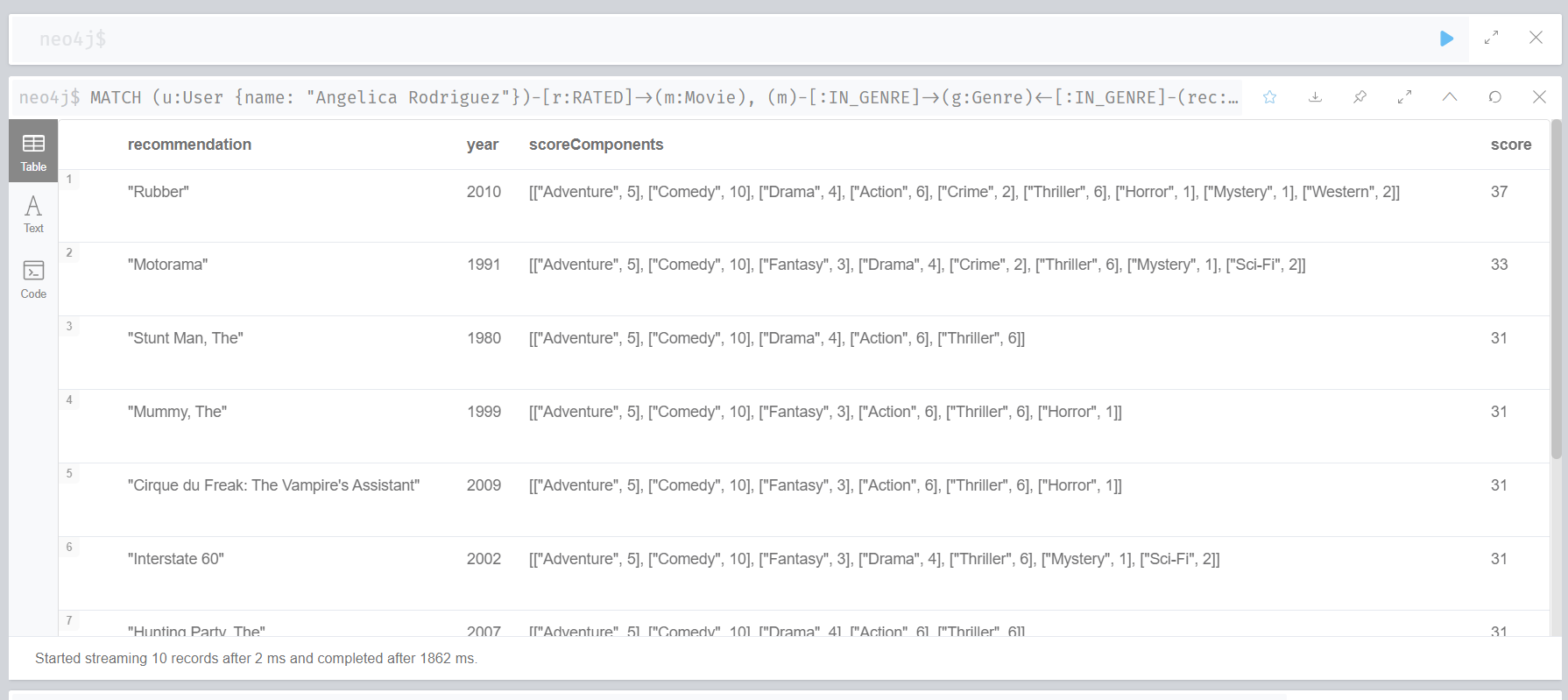
콘텐츠 요소별 가중치
영화에 대한 선호에 영향을 미치는 변인은 장르 말고도 많겠죠? 아래 알고리즘은 장르 외에 배우(a:Actor)나 감독(d:Director) 콘텐츠를 고려하는 동시에 요소별 가중치를 다르게 하는 방법입니다. 이미 분량 조절에 실패했기 때문에(ㅠㅠ) 이번에는 원리만 설명드리고 넘어가겠습니다. 아래 알고리즘은 결국 MATCH절을 통해 "오즈의 마법사(Wizard of Oz, the)" 장르, 배우, 감독별로 공통점의 수를 헤아린 뒤, RETURN절에서 각 요소마다 5, 3, 4의 가중치를 곱하고 더해 score에 저장하라는 뜻입니다.
xxxxxxxxxxMATCH (m:Movie) WHERE m.title = "Wizard of Oz, The"MATCH (m)-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(rec:Movie)WITH m, rec, COUNT(*) AS gsOPTIONAL MATCH (m)<-[:ACTED_IN]-(a:Actor)-[:ACTED_IN]->(rec)WITH m, rec, gs, COUNT(a) AS asOPTIONAL MATCH (m)<-[:DIRECTED]-(d:Director)-[:DIRECTED]->(rec)WITH m, rec, gs, as, COUNT(d) AS dsRETURN rec.title AS recommendation, (5*gs)+(3*as)+(4*ds) AS score ORDER BY score DESC LIMIT 100
콘텐츠 기반 유사도 매트릭스
이제 콘텐츠 기반 추천 알고리즘의 마지막 단계입니다! 이번에는 유사도 지표 중 하나인 자카드 지표(Jaccard Index)를 계산하는 법을 다룹니다. 자카드 지표는 매우 직관적입니다. 아래 수식 을 보시면 자카드 지표는 A와 B가 가지고 있는 요소 교집합의 원소 갯수에서 합집합의 원소 갯수를 나누어 산출합니다. 자카드 지표가 클수록 A와 B는 유사하고, 멀수록 이질적입니다.
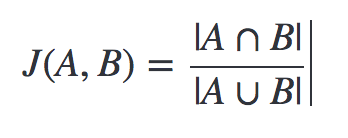
원래는 사용자별 개인화된 영화 추천을 하는 알고리즘을 살펴봐야 할 것 같지만, 다시 한 번 인셉션으로 돌아왔습니다. 자카드 지표를 활용해 인셉션과 가장 유사한 영화를 추천하는 알고리즘입니다.
아래 Cypher 코드를 살펴보면 크게 3부분으로 구성되어 있습니다. 첫 번째 부분은 자카드 지표를 산출하는 데 필요한 데이터 세트를 준비하는 단계입니다. 두 번째 단계는 자카드 지표를 계산하는 부분입니다. 마지막으로 자카드 지표에 기반해 인셉션과 가장 유사한 영화를 추천하는 부분입니다. 그럼 지금부터 덩어리별로 살펴보겠습니다!
앞선 코드들과 일관성을 유지하고 조금 더 이해하기 쉽게 만들기 위해 Neo4j 예제에 제시된 코드를 수정했습니다.
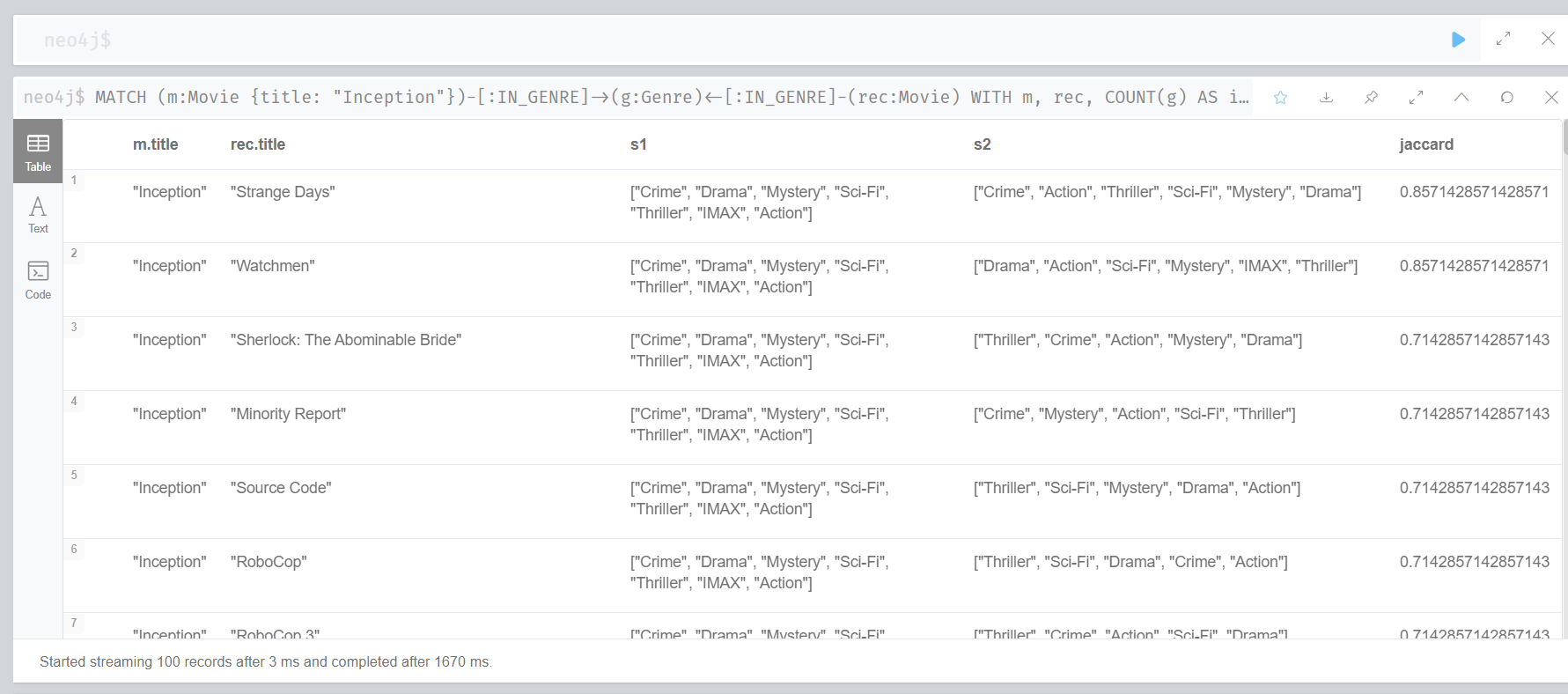
xxxxxxxxxx// 자카드 지표 계산을 위한 데이터 추출MATCH (m:Movie {title: "Inception"})-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(rec:Movie)WITH m, rec, COUNT(g) AS intersection, COLLECT(g.name) AS iMATCH (m)-[:IN_GENRE]->(mg:Genre)WITH m,rec, intersection,i, COLLECT(mg.name) AS s1MATCH (rec)-[:IN_GENRE]->(recg:Genre)WITH m,rec,intersection,i, s1, COLLECT(recg.name) AS s2// 자카드 지표 계산 WITH m,rec,intersection,s1,s2WITH m,rec,intersection,s1+[x IN s2 WHERE NOT x IN s1] AS union, s1, s2WITH m,rec,s1,s2,((1.0*intersection)/SIZE(union)) AS jaccard// 자카드 지표 기반 영화 추천RETURN m.title, rec.title, s1,s2,jaccard ORDER BY jaccard DESC LIMIT 100
첫 번째 부분로 자카드 지표를 계산하기 위한 데이터 세트를 준비합니다. A영화와 B영화의 자카드 지표를 계산하기 위해서는 두 영화의 합집합과 교집합을 알아야 합니다. 먼저 교집합입니다. 인셉션과 각 추천 영화가 공통적으로 가지고 있는 장르의 수를 도출하는 코드는 앞서 살펴본 것과 동일합니다. 다음으로 합집합입니다. 인셉션과 각 추천 영화의 합집합을 구하는 부분입니다. 먼저 인셉션에 해당하는 장르 요소를 s1에 저장하고, 다른 추천 영화에 해당하는 장르 요소를 s2에 저장합니다. 다음으로 s1+[x IN s2 WHERE NOT x IN s1] AS union로 각각의 집합에 속한 장르 요소를 중복되지 않게 union에 저장합니다.
xxxxxxxxxx// 자카드 거리 계산을 위한 데이터 추출MATCH (m:Movie {title: "Inception"})-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(rec:Movie)WITH m, rec, COUNT(g) AS intersection, COLLECT(g.name) AS iMATCH (m)-[:IN_GENRE]->(mg:Genre)WITH m,rec, intersection,i, COLLECT(mg.name) AS s1MATCH (rec)-[:IN_GENRE]->(recg:Genre)WITH m,rec,intersection,i, s1, COLLECT(recg.name) AS s2WITH m,rec,intersection,s1+[x IN s2 WHERE NOT x IN s1] AS union, s1, s2
((1.0*intersection)/SIZE(union)) AS jaccard 는 두 영화의 장르 교집합의 원소 갯수를 장르 합집합 원소 갯수로 나눠 자카드 지표를 산출하는 부분입니다.
xxxxxxxxxx// 자카드 지표 계산 WITH m,rec,s1,s2,((1.0*intersection)/SIZE(union)) AS jaccard
자카드 지표가 높은 순서로 출력해 상위 10개의 영화를 추천해주는 부분입니다.
// 자카드 거리 기반 영화 추천RETURN m.title, rec.title, s1,s2,jaccard ORDER BY jaccard DESC LIMIT 100
최종 추천 결과물입니다. 모두 같은 결과를 확인하셨나요?
이렇게 Neo4j의 Cypher 쿼리문을 사용해 가장 간단한 추천 모델인 콘텐츠 기반 영화 추천 모델을 함께 만들어 보았습니다. Neo4j 샌드박스에서 함께 연습한 내용을 조합해 더 복잡한 모델을 직접 만들어볼 수 있습니다. 아직 협업 필터링 연습도 구독자 여러분이 스스로 연습할 수 있게 남겨두겠습니다 🙂 연습을 하시다 어려운 점이나 궁금한 점이 생겼다면 언제든지 연락주세요(a072826@korea.ac.kr).
마치며
오늘 뉴스레터에서는 많은 내용을 다뤘습니다! 가장 먼저 그래프 데이터베이스의 정의와 필요성에 대해 살펴보았습니다. 그리고 가장 유명한 그래프 데이터베이스 Neo4j와 Cypher 쿼리문을 탐색했습니다. 마지막으로 Neo4j와 Cypher 쿼리문을 사용해 콘텐츠 기반 영화 추천 모델을 만들어 보았습니다. Neo4j의 샌드박스에는 다양한 그래프 기반 분석의 원리와 응용방법을 쉽고 빠르게 익힐 수 있는 재미있는 콘텐츠가 가득했습니다. 소셜 네트워크 분석(social network analysis)이나 네트워크 사이언스(network science)에 관심있는 분들께 강력 추천합니다. 이번 기사를 통해 구독자 여러분께서 데이터를 저장하는 방식이 엑셀 같은 표 뿐만 아니라 네트워크 형태로도 가능하다는 것을 체험하셨기를 기대합니다!
참고
https://medium.com/criteo-engineering/top-applications-of-graph-neural-networks-2021-c06ec82bfc18
https://shapeofdata.wordpress.com/2013/08/13/graphs-and-networks/
https://neo4j.com/download/
https://wikidocs.net/book/3724
https://www.youtube.com/watch?list=PL9Hl4pk2FsvWM9GWaguRhlCQ-pa-ERd4U&time_continue=4&v=NH6WoJHN4UA
https://neo4j.com/developer/kb/understanding-non-existent-properties-and-null-values/
