Graph database (2): Neo4j를 활용한 사기거래 탐지
안녕하세요, 뉴스레터 구독자 여러분! 데이터Hub팀 데이터 사이언티스트 문기범입니다. 지난 뉴스레터 “그래프 데이터베이스와 Neo4j”에서는 그래프 데이터베이스에 대한 설명, 가장 대표적인 그래프 데이터베이스인 Neo4j 소개, 그리고 Neo4j를 사용한 추천모델 만들기까지 함께 살펴보았습니다. 구글 검색을 해보니 아직 한국어로된 그래프 데이터베이스 관련 자료가 많지 않아 보였습니다. 그래서 이번 뉴스레터도 지난 번에 이어 Neo4j를 함께 살펴보고자 합니다 🙂
지난 뉴스레터에서 소개해드린 것처럼 Neo4j 공식 홈페이지에서 제공하는 sandbox에는 그래프 데이터베이스를 활용한 다양한 데이터 분석 튜토리얼이 준비되어 있습니다! 준비되어 있는 튜토리얼 중에 하나를 골라 그래프 데이터가 데이터 사이언스 프로젝트에서 어떻게 활용되는지, 그리고 그래프 데이터베이스가 얼마나 유용한지 함께 확인해 보면 좋을 것 같습니다.
아래 캡처화면에 따라 새로운 프로젝트를 시작해보시죠!
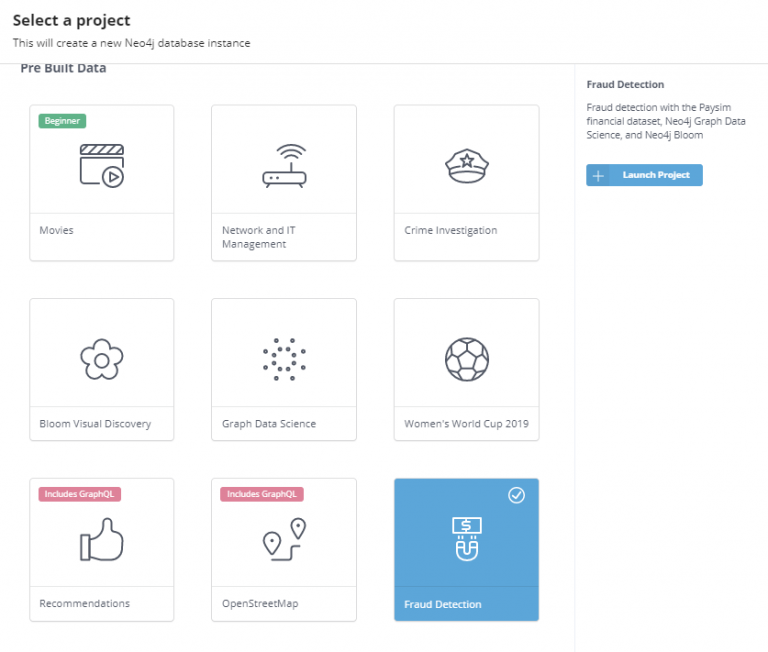
미리 준비된 튜토리얼 목록입니다. 지난 뉴스레터에서 함께 살펴본 영화 (Movies)와 추천 (Recommendations) 예제가 보이네요. 이번에는 사기 탐지 (Fraud Detection) 예제가 왠지 끌리네요. 사실 저도 이번 뉴스레터를 작성하기 위해 처음 보는 예제입니다! 그래서, 이번 뉴스레터 글은 유튜브 리액션 영상처럼 Neo4j 예제를 함께 살펴본다고 생각해주시면 감사하겠습니다. 과연 그래프 데이터를 활용한 사기 탐지는 어떻게 이루어질까요?
그래프 데이터 사이언스 라이브러리를 활용한 사기 탐지 및 검사
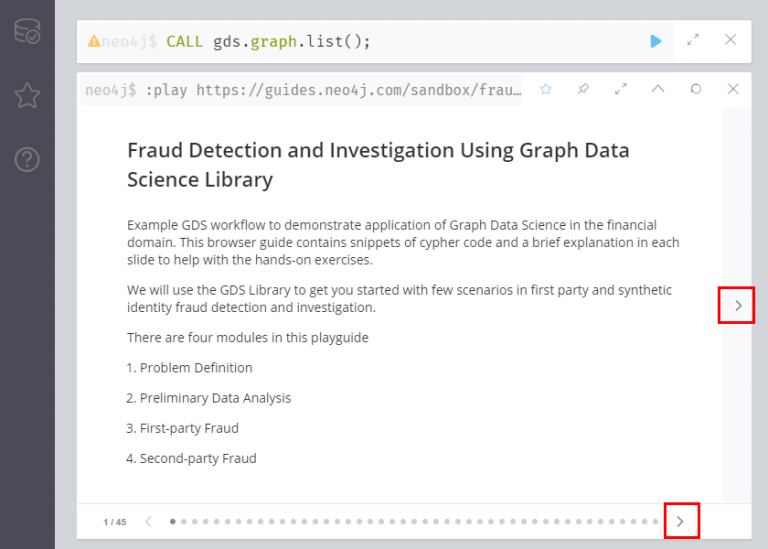
지난 번에 보았던 것과 유사한 첫화면 입니다! 가장 먼저 그래프 데이터 사이언스 (Graph Data Science, GDS) 라이브러리를 활용한 사기 탐지 및 검사라는 제목이 눈에 들어오네요. GDS 라이브러리는 그래프 데이터 분석에 유용한 여러 함수를 미리 정의해 놓은 도구 모음입니다.
이번 예제의 목적은 GDS를 활용해 금융계에서 사기 거래를 탐지하고 검사하는 어플리케이션을 제작해 보는 것입니다.
아래 빨간 네모 속 화살표 버튼을 클릭하면 다음 단계로 넘어갈 수 있습니다.
만약 크롬을 사용하는 구독자 여러분은 크롬의 한국어 번역 기능(마우스 오른쪽 → 클릭 후 한국어(으)로 번역)을 통해 한국어로도 예제를 진행할 수 있습니다. 이번 기사는 한국어로 번역된 결과를 중심으로 작성하겠습니다. 하지만, 원문과 번역본을 모두 살펴보고 이해하기 어렵거나 오역이 있는 경우에는 원문과 함께 제 해석을 덧붙이겠습니다!
저자는 이번 예제가 다음의 4개의 모듈로 이루어져있다고 설명합니다.
- 문제 정의
- 예비 데이터 분석
- 자사 사기
- 제2자 사기
첫 번째, 두 번째 모듈은 무슨 내용이 나올 지 예상이 가지만, 세 번째, 네 번째 모듈에 제시된 자사 사기 (First-party Fraud) / 제2자 사기 (Second-party Fraud)는 무슨 내용인지 모르겠네요! (사실… 저 번역이 맞는지도 의심스럽지만, 편의를 위해 그냥 저 용어를 사용하도록 하겠습니다 😂) 아마 첫 번째 모듈인 문제 정의에서 두 개념을 설명해줄 것 같습니다.
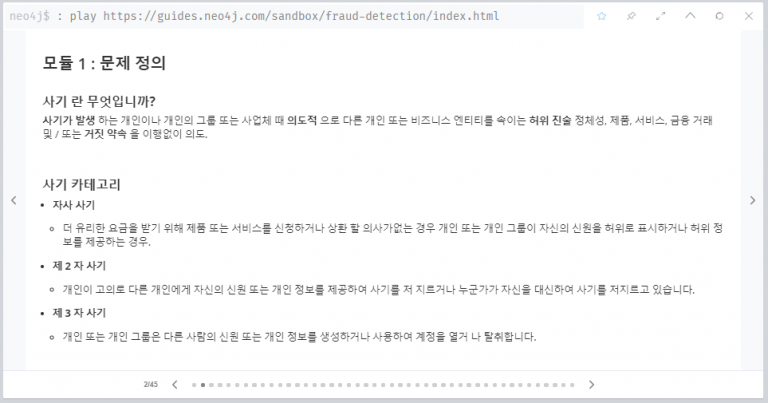
모듈 1: 문제 정의
가장 먼저 사기의 정의와 함께 자사 사기, 제2자 사기에 대한 설명이 제시되었습니다. 사기에 대한 설명에서 ‘엔티티 (entity)’라는 표현이 사용된 게 눈에 들어오네요. 지난 뉴스레터에서 그래프에서 노드 (node)가 엔티티로도 불리는 것을 알아봤었는데요, 여기서는 노드가 될 수 있는 행위 주체 정도로 이해할 수 있습니다.
모듈 2: 예비 데이터 분석
두 번째 모듈에서는 예제에 필요한 모방 데이터를 생성합니다.
연습 1 : 데이터베이스 스키마
가장 먼저 아래 쿼리를 입력해 데이터 세트의 스미키마를 확인합니다. 쿼리를 입력하는 방법은 간단합니다. 위 명령어창에 아래 써있는 Cypher명령어를 타이핑 한 후 오른쪽 파란색 삼각형 버튼을 누르면 됩니다. 회색 텍스트 박스를 클릭하면 자동으로 쿼리문이 입력되지만, 연습삼아 직접 타이핑 하는 것을 추천드립니다. 또, 한국어 번역 상태에서는 CALL 등의 명령어까지 ‘전화’로 번역되기 때문에 마우스 오른쪽 버튼 ‘한국어(으)로 번역’ 메뉴를 다시 한 번 클릭해 영어로 진행해주세요.
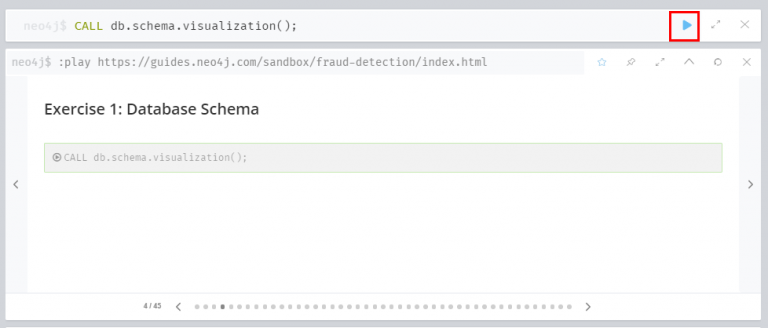
쿼리문을 입력하면 아래처럼 그래프 데이터의 스키마를 한눈에 확인할 수 있는 네트워크 플롯이 출력됩니다.

연습 2 : 통계
아래 쿼리문을 입력하면, APOC 라이브러리를 사용하여 노드 수, 노드 레이블, 관계, 관계 유형, 속성 키 및 통계값이 제공됩니다.
CALL apoc.meta.stats();연습 3 : 노드
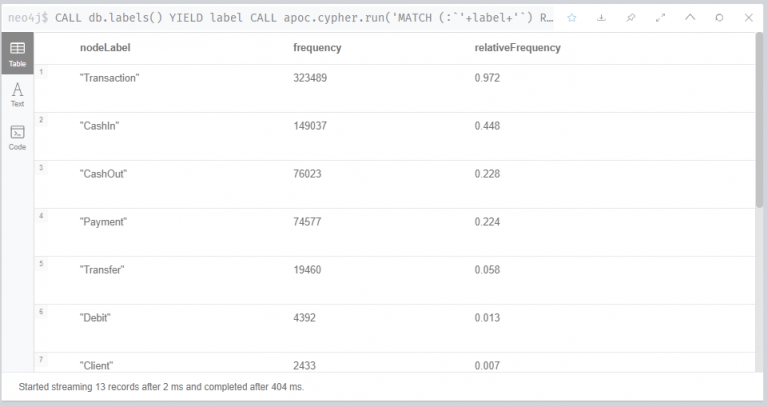
모든 노드 레이블과 해당 *주파수를 나열합니다. 이것은 데이터베이스의 모든 노드 레이블을 반복하고 빈도 및 상대 빈도를 계산하여 수행됩니다.
※ 빈도가 맞는 번역입니다.

각 행별로 쿼리문을 함께 살펴볼까요?
1: db의 레이블들을 label이라는 컬럼으로 만든다.
2-3: 각 레이블별로 등장횟수를 카운팅해 value의 freq으로 저장한다.
4: label과 freq 컬럼 선택 (value.freq으로 값을 추출해 freq이라는 이름의 새로운 컬럼을 선택함)
5: 전체 노드 카운트의 합 산출
6-7: 소숫점 3째자리까지 전체 노드 카운트에서 해당 노드 등장횟수가 차지하는 비중 산출
8: 출력 컬럼 결정, 등장횟수에 따라 내림차순 정렬
즉, 위 Cypher문은 각 노드별(nodeLabel)로 등장 횟수(frequency)와 그것이 전체 노드의 등장 횟수에서 차지하는 상대적 비율(relativeFrequency)을 출력하고 있습니다. 아래 표는 출력 결과입니다!
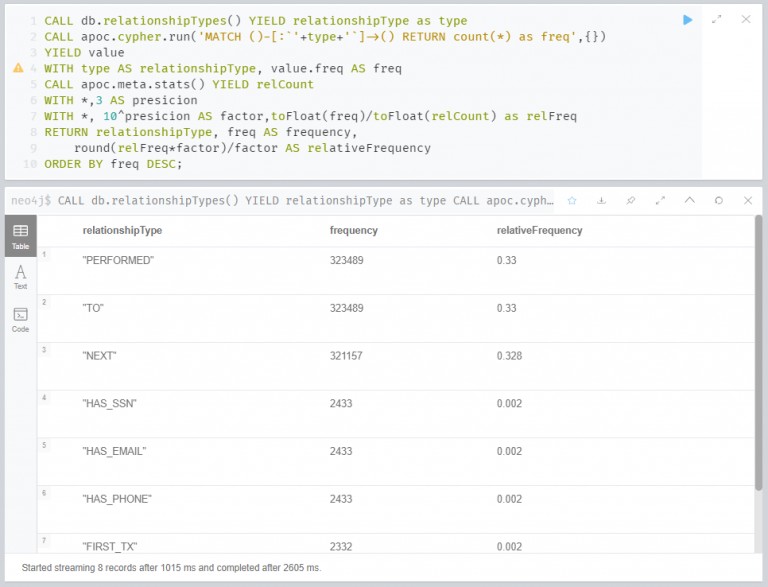
연습 4 : 관계 유형
다음으로는 모든 관계유형과 해당 빈도에 대한 집계입니다. 그래프 데이터에서 관계는 엣지(edge)로 표현됩니다. 아래 이미지는 이를 위한 Cypher와 출력결과 입니다. 위에서 한 노드 레이블 집계와 대동소이하기 때문에 상세 설명은 생략하겠습니다. 노드를 검색할 때와 엣지를 검색할 때의 차이만 살펴보면 되겠습니다.
노드 탐색: ‘MATCH (:`’+label+’`) RETURN count(*) as freq’
엣지 탐색: ‘MATCH ()-[:`’+type+’`]->() RETURN count(*) as freq’
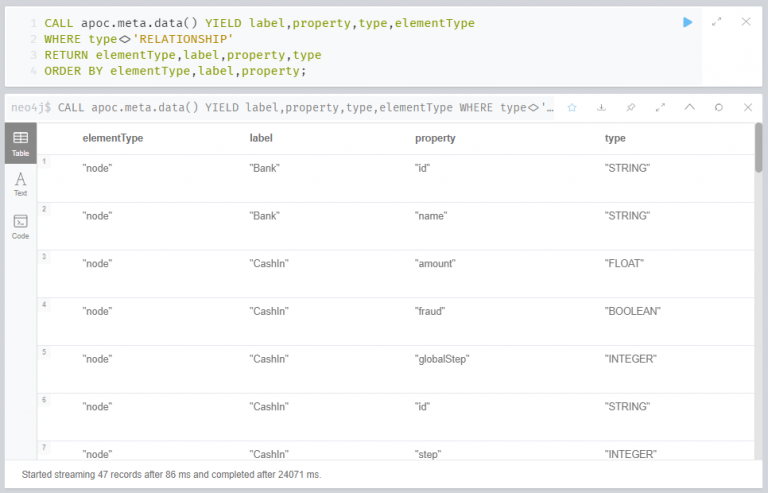
연습 5 : 노드 및 관계 속성
다음으로 모든 노드 및 관계 속성을 나열합니다.
WHERE type<>’RELATIONSHIP’ 데이터의 타입이 관계인 것만을 필터링합니다.
이 표에서 레이블은 노드의 종류라고 이해할 수 있습니다. 즉, 사기거래 데이터 세트에 포함된 노드는 “은행 (bank)”, “입금 (CashIn)” 등이 있는 것입니다. 은행 레이블은 id와 이름 (name)을 속성으로 갖고, 입금 레이블은 금액 (amount), 사기여부 (fraud), globalStep (?), id, step(?), ts (?) 등의 속성을 갖습니다. globalStep, step, ts가 뜻하는 것이 무엇인지는 잘 모르겠네요 😢
연습 6 : 거래 유형
이 데이터베이스에는 다섯 가지 유형의 *트랜잭션이 있습니다.모든 거래 유형의 모든 거래를 반복하여 총 시장 가치, 상대적 시장 가치, 거래 수 등과 같은 모든 거래 유형 및 해당 메트릭을 나열합니다.
* 거래
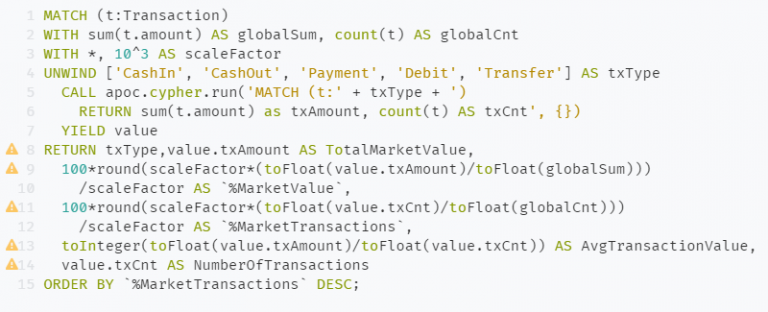
새로운 Cypher문이 나왔으니 함께 살펴보겠습니다.
1: MATCH expression을 사용해 레이블이 Transaction인 노드를 t로 정의합니다.
2: . operator를 사용해 t 의 amount 속성을 출력한 후 sum()함수를 사용해 모두 더한 값을 globalSum으로 정의합니다. count(t)로 Transaction 노드의 수를 globalCnt 에 할당합니다.
3: with *로 이전 데이터를 그대로 다 가지고 온 상태에서 10^3을 scaleFactor에 할당
4-7: UNWIND 는 리스트를 행으로 바꿔주는 expression입니다. 자세한 설명은 여기를 참조해 주세요. 다섯가지 거래 유형별로 row를 만든 뒤 거래유형별 거래 금액의 합(sum(t.amount) as txAmount)과 횟수(count(t) as txCnt)를 집계하고 value에 할당합니다.
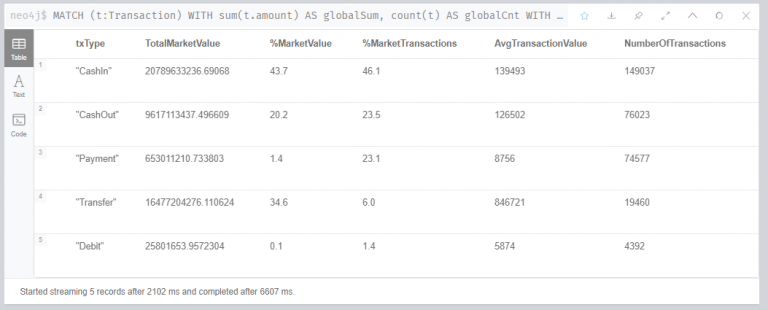
8-14: 거래유형(txType), 거래유형별 금액 합계(TotalMarketValue), 전체 거래금액에서 차지하는 비율(%MarketValue), 전체 거래 횟수에서 차지하는 비율(%MarketTransactions), 거래금액 평균(AvgTransactionsValue), 거래횟수(NumberOfTransactions) 출력
15: 전체 거래 횟수에서 차지하는 비율 순으로 내림차순 정리
아래 표는 출력 결과입니다.
이렇게 두 번째 모듈이 끝났습니다!
- 데이터베이스 스키마 및 크기
- 노드 레이블 및 관계 유형 분포
- 노드 및 관계 속성
- 거래 유형 분포
모듈 3 : 자사 사기 (First-party fraud)
- 개인 식별 정보 (PII)를 공유하는 클라이언트 식별
- 커뮤니티 감지 알고리즘 (약하게 연결된 구성 요소)을 사용하여 PII를 공유하는 클라이언트 클러스터 식별
- 쌍별 유사성 알고리즘 (노드 유사성)을 사용하여 공유 식별자를 기반으로 클러스터 내에서 유사한 클라이언트 찾기
- 연결 중심성 (Degree Centrality)을 사용하여 클러스터의 클라이언트에 사기 점수 계산 및 할당
- 할당 된 사기 점수를 사용하여 클라이언트를 잠재적 사기꾼으로 분류
아직도 갈길이 머네요!! 지금부터는 속도를 높여 중요한 부분만 함께 살펴보겠습니다.
연습 1, 작업 1 : PII를 공유하는 클라이언트 식별
연습 1은 두 부분입니다. 먼저, 이메일, 전화번호, 사회보장번호가 일치하는 사용자쌍을 출력합니다. freq는 일치하는 PII요소의 수입니다. 두 번째는 마지막 출력부분에서만 전체 표 대신 PII가 일치하는 사용자의 수를 산출합니다.
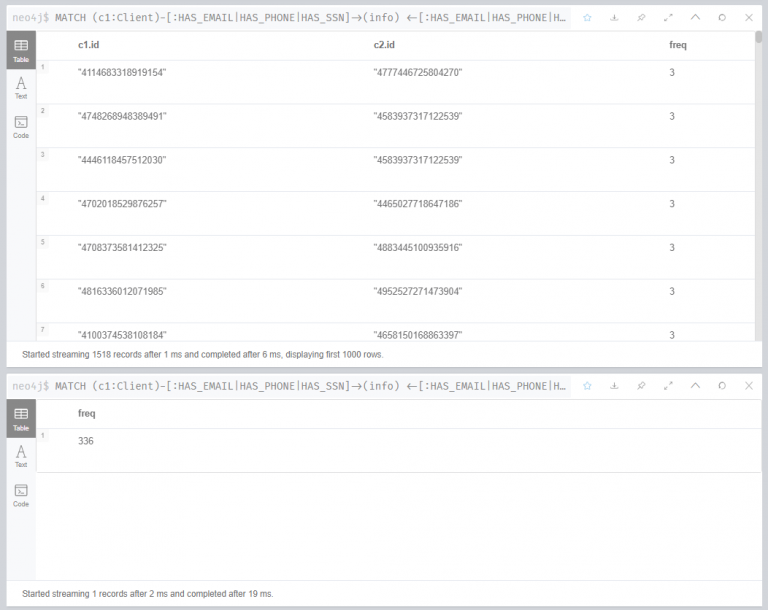
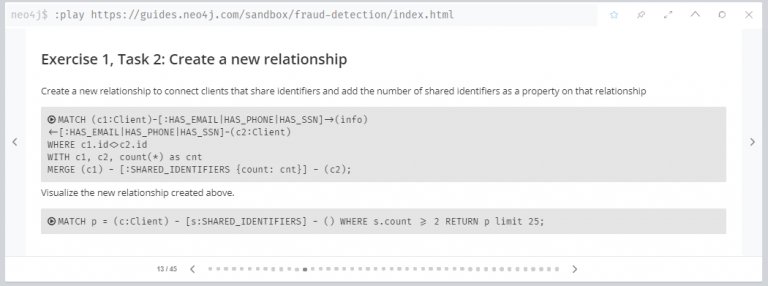
연습 1, 작업 2 : 새 관계 만들기
식별자를 공유하는 클라이언트를 연결하는 새 관계(SHARED_IDENTIFIERS)를 만들고 해당 관계의 속성으로 공유 식별자 수({count: cnt})를 추가합니다.
아래 쿼리는 위에서 새롭게 만든 관계를 25개 출력해 시각화했습니다.
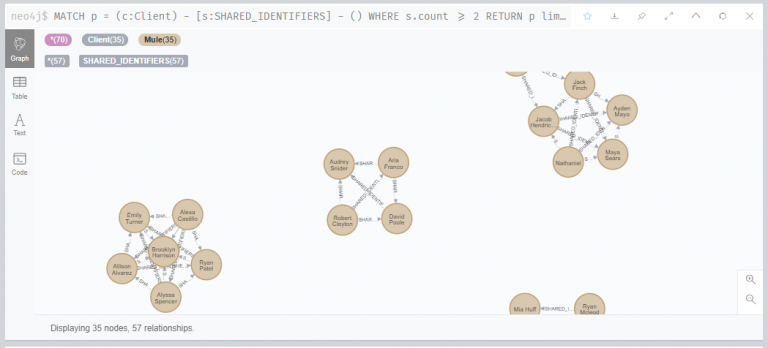
연습 1 종료
이 연습에서는 아래와 같은 작업을 수행했습니다.
PII를 공유하는 모든 클라이언트 쌍을 식별하고 해당 클라이언트 수를 계산했습니다.
PII를 공유하는 클라이언트 쌍을 연결하기위한 새로운 관계를 생성했습니다.
연습 2 : PII를 공유하는 클라이언트 클러스터 식별
PII를 공유하는 클라이언트 클러스터 식별은 GDS 라이브러리에 구현 된 커뮤니티 감지 알고리즘 중 하나를 실행하여 수행됩니다.
Weakly Connected Components를 사용하여 동일한 집합의 모든 노드가 연결된 구성 요소를 형성하는 연결된 노드 그룹을 찾습니다. WCC는 그래프의 구조를 이해하기 위해 분석 초기에 자주 사용됩니다.
자세한 정보 : WCC 문서
이 연습에서는 WCC에 맞게 그래프를 재구성하고 그래프 카탈로그 함수를 사용하여 그래프를 메모리에 로드하고 그래프 알고리즘을 실행하는 방법도 배웁니다.
연습 2, 작업 0 : 그래프 모양 변경 및 로드
첫 번째 단계는 알고리즘을 실행하기 전에 입력 그래프의 모양에 대해 생각하는 것입니다. 그런 다음 알고리즘 요구 사항을 충족하도록 그래프의 모양을 변경하여 결국 의미있는 결과를 얻습니다.
이 연습에서는 커뮤니티 감지 알고리즘을 사용하여 커뮤니티 / 클러스터 클라이언트를 찾을 계획입니다.
커뮤니티 감지 알고리즘은 입력으로 단립형 그래프 (단일 유형의 노드 및 노드 간 관계)를 예상합니다. 따라서 클라이언트 노드와 해당 노드를 연결하는 관계 만 포함하는 메모리에 그래프를 투영해야합니다.
그래프 프로젝션 및 그래프 카탈로그에 대한 추가 정보 : 그래프 카탈로그
연습 2, 작업 1 : 메모리 추정
인메모리 그래프를 만들기 전 충분한 메모리가 있는지 확인하기 위해 메모리 추정치를 확인하는 과정입니다. 튜토리얼의 저자는 중요한 과정이라고 주장하고, 저도 그렇게 생각하지만… 분량조절을 위해 자세한 설명은 생략하겠습니다!
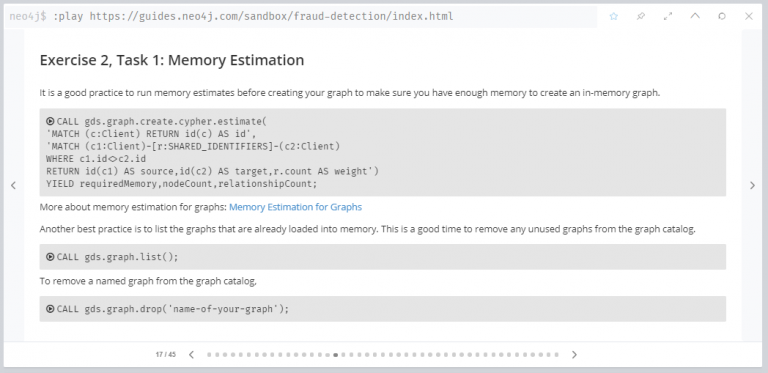
연습 2, 작업 2 : WCC를 위한 그래프 투영
네이티브 프로젝션을 사용하여 단립형 그래프를 메모리에 로드해 보겠습니다. 이 튜토리얼에서는 WCC 알고리즘을 실행하기 위해 그래프 이름으로 ‘WCC’를 선택했습니다.

연습 2, 작업 3 : 사전 실행 검사
튜토리얼 저자는 두 가지 추가적인 사전 검사를 제안합니다.CALL gds.wcc.stream.estimate('WCC');
CALL gds.wcc.stats('WCC');
연습 2, 작업 4 : WCC 알고리즘 실행
스트림 모드
WCC를 실행하고 결과를 브라우저로 다시 스트리밍
결과는 데이터베이스에 기록되지 않습니다.
아래 Cypher 쿼리는 중요한 쿼리니까 함께 살펴보죠!
1: 앞 소문자 wcc는 GDS에 포함된 weekly connected cluster 알고리즘을 말하며 뒷 대문자 `WCC`는 앞서 만든 단립형 그래프를 말합니다.
2: WCC 알고리즘 실행 결과를 componentId와 nodeId로 산출합니다.
3: componentId 컬럼명을 cluster로 변경, nodeId를 client라는 이름의 node로 변경합니다.
4: 각 cluster별로 client 노드의 id를 모두 모아 clients라는 이름의 컬럼의 한 셀에 넣습니다.
5: 각 클러스터별로 클라이언트의 수를 clusterSize에 할당합니다.
6: 클라이언트 수가 1보다 큰 클러스터만 필터링합니다.
7-8: cluster, clusterSize, clients 컬럼 추출 후 클러스터 사이즈에 따라 내림차순 정리합니다.
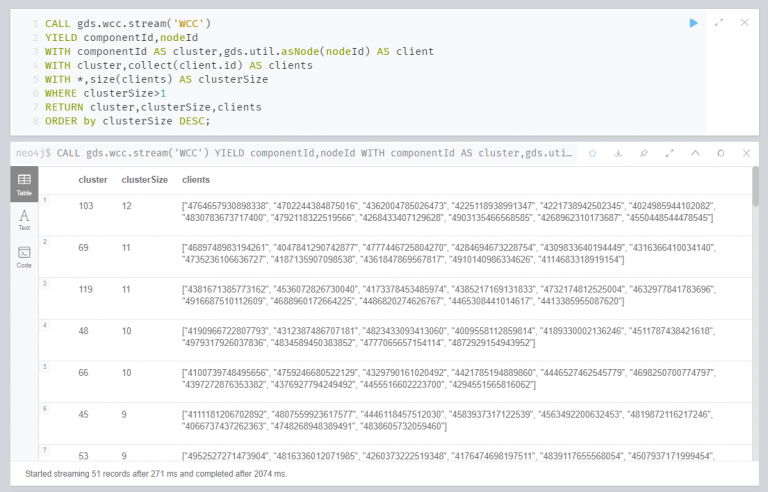
연습 2, 작업 5 : 결과를 데이터베이스에 씁니다.
쓰기 모드를 사용하면 결과를 데이터베이스에 다시 쓸 수 있습니다.
쓰기 모드 대신 여기에서는 cypher를 사용하여 크기 (> 1)를 기준으로 클러스터를 필터링 한 다음 클라이언트 노드에 속성을 설정합니다.
작업 4와 달리 결과를 데이터베이스에 기록합니다. 쿼리가 크게 다르지 않습니다. 다만, 뒷 부분에서 그래프 데이터베이스에 저장하기 위해 다시 clients에 저장되어 있는 nodeId를 풀어서 Client 노드에 firstPartFraudGroup 속성을 cluster로 설정합니다.
CALL gds.wcc.stream('WCC')
YIELD componentId,nodeId
WITH componentId AS cluster,gds.util.asNode(nodeId) AS client
WITH cluster, collect(client.id) AS clients
WITH *,size(clients) AS clusterSize
WHERE clusterSize>1
UNWIND clients AS client
MATCH(c:Client)
WHERE c.id=client
SET c.firstPartyFraudGroup=cluster;
연습 2, 작업 6 : 클러스터 수집 및 시각화
PII를 공유하는 클라이언트 클러스터를 시각화합니다.
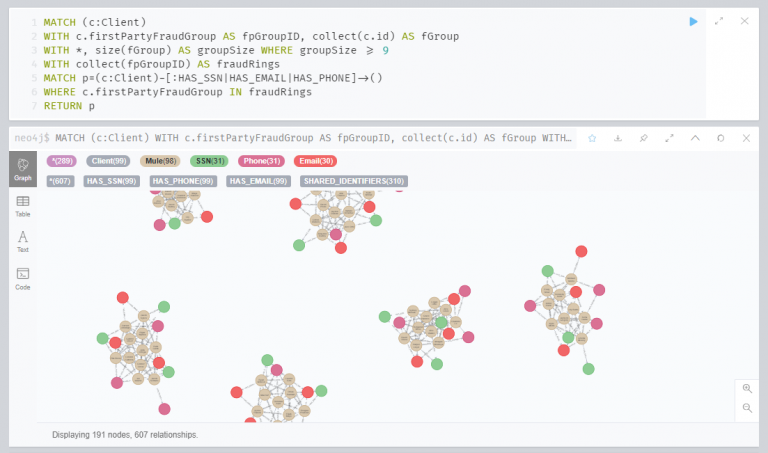
(확대)
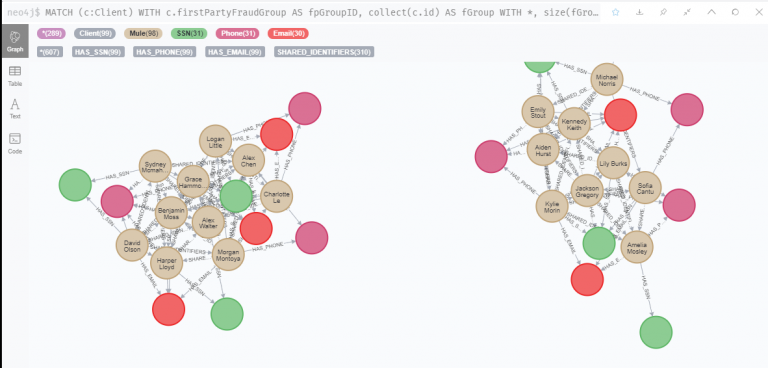
연습 3 : 클러스터 내에서 유사한 클라이언트 찾기
GDS 라이브러리에 구현 된 paiwrise 유사성 알고리즘 중 하나를 실행하여 같은 클러스터에 포함된 유사 클이언트를 찾습니다.
노드와의 관계를 기반으로 유사한 노드를 찾기 위해 노드 유사성을 사용했습니다. 노드 유사성은 자카드(Jaccard) 거리에 기반해 계산합니다. 자카드 거리는 한 쌍의 두 노드와 관련된 모든 노드의 수에서 두 노드 모두와 관련된 노드의 수가 차지하는 비율로 계산됩니다.
추가 정보: 노드 유사성 문서
노드 유사성 알고리즘은 이분 그래프 (두 가지 유형의 노드 및 노드 간의 관계)에서 작동합니다. 여기서 우리는 클라이언트 노드와 세 개의 식별자 노드 를 메모리에 투영합니다. 이러한 식별자를 공통으로 갖는 클라이언트는 서로 유사합니다.
연습 3, 작업 1 : 그래프 만들기
여기서는 유사성 알고리즘을 실행하기 위해 Cypher를 사용해 인메모리 그래프를 만듭니다. 이 튜토리얼에서는 노드 유사성 알고리즘을 실행하기 위해 그래프 이름으로 ‘유사성(Similarity)’을 선택했습니다.
쿼리를 살펴볼까요?
가장 먼저 gds.graph.create.cypher() 는 그래프 프로젝션을 하는 Syntex로 아래 세 가지 필수 인자가 존재합니다.
graphName, nodeQuery, relationshipQuer
즉, 아래 Cypher 쿼리에서 , 를 준으로 각각 그래프 이름, 노드를 만들기 위한 쿼리, 관계를 만들기 위한 쿼리라는 것을 알 수 있습니다.
firstPartyFraudGroup에 포함된 Client 노드를 찾아서 해당 노드의 id를 id로, 레이블을 labels로 저장합니다.
그리고 이 결과를 Email , Phone, SSN 노드와 병합(UNION) 하네요.

연습 3, 작업 2 : 스트리밍 노드 유사성 결과
일단 그래프가 만들어지면 gds에 내장된 함수를 사용해 노드 유사도를 간단하게 산출할 수 있습니다.
CALL gds.nodeSimilarity.stream('Similarity',{topK:15})
YIELD node1,node2,similarity
RETURN gds.util.asNode(node1).id AS client1,
gds.util.asNode(node2).id AS client2,similarity
ORDER BY similarity;
연습 3, 작업 3 : 인메모리 그래프에 유사성 점수 기록
알고리즘의 출력을 노드 또는 관계 속성으로 작성하여 메모리 내 그래프를 변경할 수 있습니다.
Mutate 모드는 첫 번째 알고리즘의 출력이 파이프 라인의 두 번째 알고리즘에 대한 입력으로 사용되는 파이프 라인에서 둘 이상의 알고리즘을 실행할 때 매우 유용합니다. Mutate 모드는 쓰기 모드에 비해 매우 빠르며 알고리즘 실행 시간을 최적화하는 데 도움이됩니다.
R의 dplyr 라이브러리의 mutate와 유사하네요.
여기에서는 각 노드별로 각 노드와 자카드 점수 기준 상위 15개의 노드까지 SIMILAR_TO라는 관계로 정의했습니다.
CALL gds.nodeSimilarity.mutate('Similarity',
{topK:15, mutateProperty:'jaccardScore', mutateRelationshipType:'SIMILAR_TO'});
연습 3, 작업 4 : 인메모리 그래프의 결과를 데이터베이스에 기록
메모리 상에서 작업하던 결과물을 다시 데이터베이스에 기록합니다.
CALL gds.graph.writeRelationship('Similarity','SIMILAR_TO','jaccardScore');연습 3, 작업 5 : 시각화
새로 생성 된 SIMILAR_TO관계와 유사성 점수를 기반으로 한 유사 클라이언트의 관계를 살펴 보겠습니다.
firstPartyFraudGroup 에 포함된 노드가 9개 이상인 그룹을 뽑아 시각화해 보았습니다. 네트워크 안에 옹기종기 모여있는 클라이언트 노드가 귀엽게 보입니다.
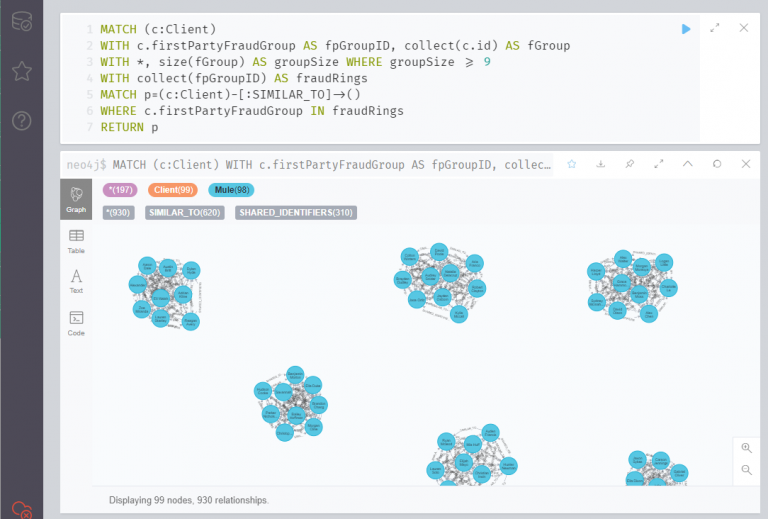
연습 4 : 자사 사기 점수
이 단계에서는 `jaccardScore` 에 따라 가중된 유사관계를 기반으로 이전 단계에서 식별된 클러스터의 클라이언트에 사기 점수( `firstPartyFraudScore` )를 계산하고 할당 합니다.
중심성 알고리즘 중 하나인 연결 중심성(Degree Centrality)을 사용하여 클러스터의 특정 노드에 대한 수신 및 송신 관계에 jaccardScore를 추가하고 합계를 해당하는 firstPartyFraudScore로 할당합니다. 이 점수는 식별자 공유 측면에서 클러스터의 다른 많은 클라이언트와 유사한 클라이언트를 나타냅니다.
여기서 가정은 firstPartyFraudScore가 높을수록 사기를 저지를 가능성이 더 크다는 것입니다.
연습 4, 작업 1 : 정도 중심성을 사용하여 중심성 점수 계산
CALL gds.alpha.degree.stream('Similarity',
{nodeLabels:['Client'],relationshipTypes:['SIMILAR_TO'],
relationshipWeightProperty:'jaccardScore'})
YIELD nodeId,score
RETURN gds.util.asNode(nodeId).id AS client,score
ORDER BY score DESC;
연습 4, 태스크 2 : 데이터베이스에 정도 중심성 쓰기
알고리즘 쓰기 모드를 사용하여 중심성 점수를 firstPartyFraudScore 으로 데이터 베이스에 기록합니다. 즉, 작업 1에서 확인한 값을 데이터 베이스에 저장하는 것입니다.
CALL gds.alpha.degree.write('Similarity',{nodeLabels:['Client'],
relationshipTypes:['SIMILAR_TO'],
relationshipWeightProperty:'jaccardScore',
writeProperty:'firstPartyFraudScore'});
연습 4, 작업 3 : 사기 점수를 기반으로 클라이언트에 레이블 추가
firstPartyFraudster 속성을 설정합니다. 여기서 firstPartyFraudster 성을 갖게된 클라이언트가 부정이용자로 예측된 사람입니다. MATCH(c:Client)
WHERE exists(c.firstPartyFraudScore)
WITH percentileCont(c.firstPartyFraudScore, 0.8)
AS firstPartyFraudThreshold
MATCH(c:Client)
WHERE c.firstPartyFraudScore>firstPartyFraudThreshold
SET c:FirstPartyFraudster;
위에서 했던 시각화 쿼리를 다시 한 번 입력해볼까요? 이번에는 부정 사용자로 의심되는 클라이언트들이 붉은 색으로 표시된 것을 확인할 수 있습니다!
MATCH (c:Client)
WITH c.firstPartyFraudGroup AS fpGroupID, collect(c.id) AS fGroup
WITH *, size(fGroup) AS groupSize WHERE groupSize >= 9
WITH collect(fpGroupID) AS fraudRings
MATCH p=(c:Client)-[:SIMILAR_TO]->()
WHERE c.firstPartyFraudGroup IN fraudRings
RETURN p
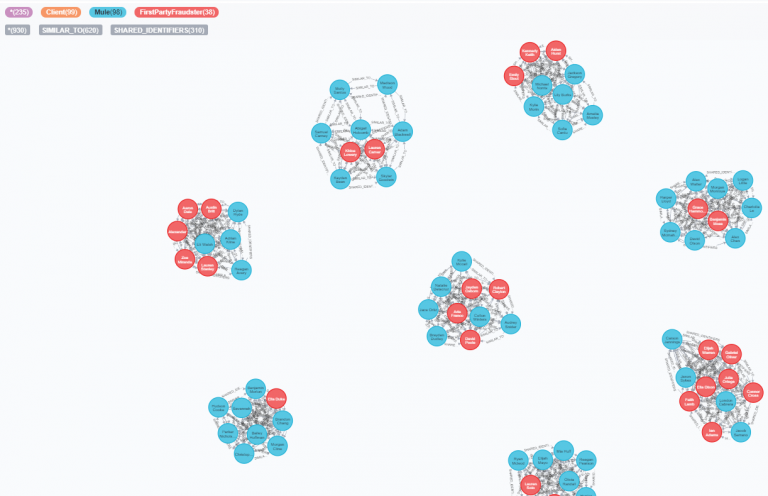
모듈 3 : 종료
이 모듈에서는 다음 작업을 수행했습니다.
PII를 공유하는 클라이언트 클러스터 확인
공유된 PII를 기반으로 클라이언트 쌍별 유사도 계산
first-party 사기 점수 계산
first-party 부정 이용자 식별
마치며
이렇게 함께하는 튜토리얼은 여기서 멈추려고 합니다. 아직 second-party 부정이용 탐지 절차가 남았지만, 이것은 구독자 여러분이 스스로 도전해보실 수 있게 남겨두겠습니다. 비록 가상 데이터이고, 실제 부정이용 탐지 알고리즘에 비해 간소화된 알고리즘이었지만, 그래프 데이터베이스의 구조와 Cypher 쿼리 이용방법에 대해 조금 더 친숙해진 것 같습니다.
아직 어색하고 사용법이 익숙하지 않아서 그런지 기존 데이터 프레임을 활용해 알고리즘을 개발하는 것에 비해 조금 복잡하고 어렵게 느껴지네요. 하지만 분석 과정에서 결과 시각화를 바로바로 해볼 수 있는 것은 흥미롭고 좋았습니다. 특히 알록달록한 색감이 너무 귀여웠습니다. 저는 그랬는데, 여러분은 어떠셨을지 궁금합니다! 혹시 이번 뉴스레터와 관련해 궁금하거나 건의하실 점이 있다면 언제든지 a072826@korea.ac.kr으로 연락주세요 🙂 그럼 또 다음에 더 재미있는 뉴스레터 기사로 찾아뵙겠습니다! 감사합니다.
