안녕하세요 데이터Hub 팀 최하림입니다. 단어 임베딩 모델인 Word2Vec에 대해 파헤쳐 봅시다. 우선, 데이터 Hub팀의 논문추천시스템이 사용한 언어모델 TF-IDF 와 어떤 차이가 있는 지부터 알아볼까요?
TF-IDF는
횟수(Frequency) 기반 모델로 TDM(Term-Document
Matrix) 내 중요도를 산출하는 모델입니다. 핵심어 추출, 유사도 비교 및 검색 결과 순위 결정을 위해 단어의 특정 문서내 중요도를 산출하는 통계적 가중치 알고리즘입니다. Wod2Vec 은 추론(Prediction) 기반으로 단어를 벡터
평면에 배치하여 단어 벡터 간 연산을 통해 결과를 추론하는 모델입니다. CBOW, Skip-gram 이라는
모델이 있죠. 머신 러닝에서 자연어 처리를 위해 자연어를 벡터화하여 임베딩할 때 많이 사용하는 모델입니다.
D1: the sky is blue, D2: the sky is not blue 라면 TF-IDF를 적용했을 때 not이라는 단어가 D2 와의 유사도가 높게 나오겠죠?
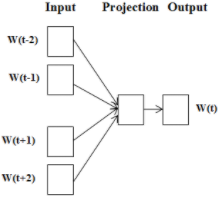
그림1.
Word2vec에서 단어의 벡터 구하는 방법
Word2Vec
은 주변 단어 기반으로 해당 위치에 나타날 수 있는 단어를 추론하는 방법으로, 컨텍스트에서
단어의 평균을 적용하여 softmax를 계산합니다. 코드를
살펴보면 다음과 같습니다. 물론 실무에서는 package 나 library 를 사용하겠죠?
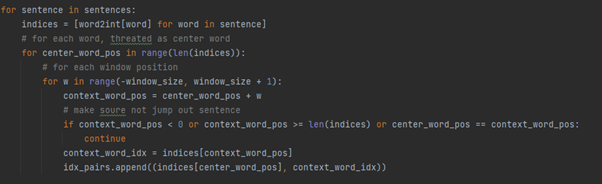
그림2.
Word2Vec 에서 단어의 벡터를 구하는 코드
TF-IDF와 Word2Vec 모두 outdated
하다는 의견이 있는데요. TF-IDF, Word2Vec의 기본원리를 알면 이후 적용되는
횟수기반과 추론기반 임베딩을 모두 사용하는 glove나 fasttext,
bert 와 같은 신경망 모델들에 대해서도 이해하기 쉬우실 것입니다.
Word2vec 이 적용된 모델은 그래프 모델에서도 사용된답니다. 단어를
임베딩시키는 방법으로 그래프에서의 노드를 임베딩시킵니다.
노드를 임베딩시키는 방법으로 deepwalk, node2vec 모델이 있습니다. Node u에서 랜덤으로 이동할 때 (random walk) node v 에 도달할 확률을 파악합니다.
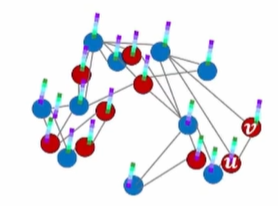
그림3.
그래프에서 노드u 에서 노드v 로 갈 확률
다음은 node u에서 node v로 갈 확률을 통해 word2vec 으로 노드의 임베딩을 구하는 과정을 코드로 나타낸 것입니다.
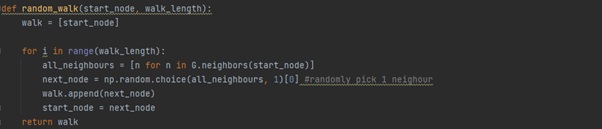
그림4.
노드u 에서 v로 갈 확률
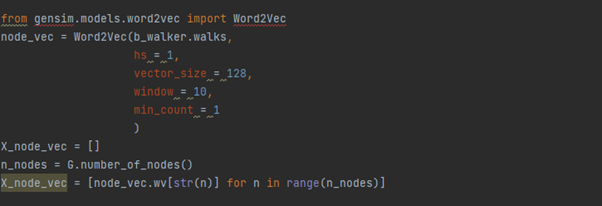
그림5.
확률을 통해 노드의 임베딩을 word2vec으로 구하는 코드
조금
더 자세히 살펴보자면, deepwalk 에서 loss 를
최소화 하기 위해 노드의 feature들의 차이를 최소화하는 방향으로 해서 구합니다.

Node2vec 은 단순 random walk가 아니라 biased random walk 방법을 사용하는데, 이 때 파라미터들을
설정합니다. q1은 starting node 로 다시 돌아오는
확률(local exploration), q2(global exploration)는 starting node 로부터 멀어질 확률로, 파라미터 설정을 통해
local exploration에 중점을 둘 것 인지 global
exploration에 중점을 둘 것인지 결정합니다. 마치 그래프 순회에서 bfs, dfs 와 같죠?
이렇게 구한 값으로
word2vec 원리를 이용한다면 node 들의 임베딩 값이
나오게 됩니다.
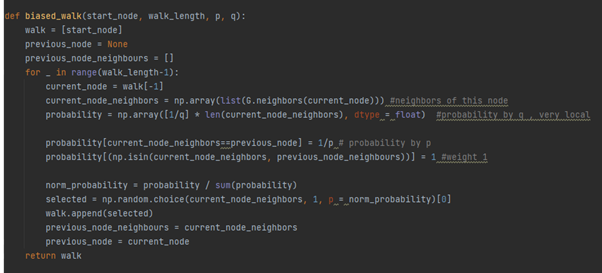
그림 6.
Biased random walk
Word2vec
에 이어서 그래프의 임베딩을 알아보았습니다. 직관적으로 이해할 수 잇는 deep walk , node2vec 에 이해했다면 gnn의 다른
우수 한 모델들을 살펴 보는 건 어떨까요?
감사합니다
