DATA@KU 뉴스레터 독자 여러분 안녕하세요. 디지털정보처 데이터Hub팀에 새로 합류하여 데이터 사이언티스트로 일하게 된 공 주입니다. 저는 사회학 전공으로 박사과정까지 마쳤고, 다년간 통계 및 데이터 분석에 기반해 다양한 연구 과제를 수행해 왔습니다. 디지털 전환에 대한 연구를 진행하면서, 디지털 전환이 우리 사회를 근본적으로 변화시키는 추동력이 될 것이라는 생각에 데이터 과학을 집중적으로 공부하게 되었습니다. 자연어 처리(Natural Language Processing, NLP) 기술에 특히 관심이 많습니다. 오늘은 자연어 처리 기술의 역사에 대해 간략하게 소개해 드리고자 합니다.
자연어(Natural Language)는 자바(Java)나 파이썬(Python)과 같이 인간이 만들어낸 인공 언어와 대비되는 개념으로 우리가 일상 생활에서 사용하는 언어를 의미합니다. 자연어 처리는 컴퓨터가 자연어를 이해하고 분석할 수 있도록 하는 기술로, 데이터 과학과 인공지능(AI) 분야에서 중요한 기술 중에 하나라고 할 수 있습니다. 딥러닝 기술이 크게 발전하면서 급속하게 성장하고 있는 분야이기도 합니다. 최근에는 트랜스포머(Transformer) 아키텍처(Vaswani et al., 2017)에 기반한 거대언어모델(Large Language Model, LLM)이 우리의 삶에도 큰 영향을 미치고 있습니다.
자연어 처리 기술이 활용된 대표적인 서비스로는 구글의 어시스턴트(Assistant), 애플의 시리(Siri)와 같은 음성 인식 가상 비서 서비스가 있습니다. 음성 인식 가상 비서 서비스는 자연어를 인식해 사용자의 요구사항을 이해하고 그 결과를 자연어로 처리하는 기술이 활용되고 있습니다. 또, 외국어로 작성된 글을 읽거나 여행지에서 외국인과 소통하기 위해 사용하는 번역 앱들 역시 기계번역이라는 자연어 처리 기술의 예라고 할 수 있습니다. 2022년 11월 경에 프로토타입이 발표된 이후 우리의 삶에 빠르게 스며들고 있는 chatGPT도 자연어 처리 기술이 활용된 것입니다.
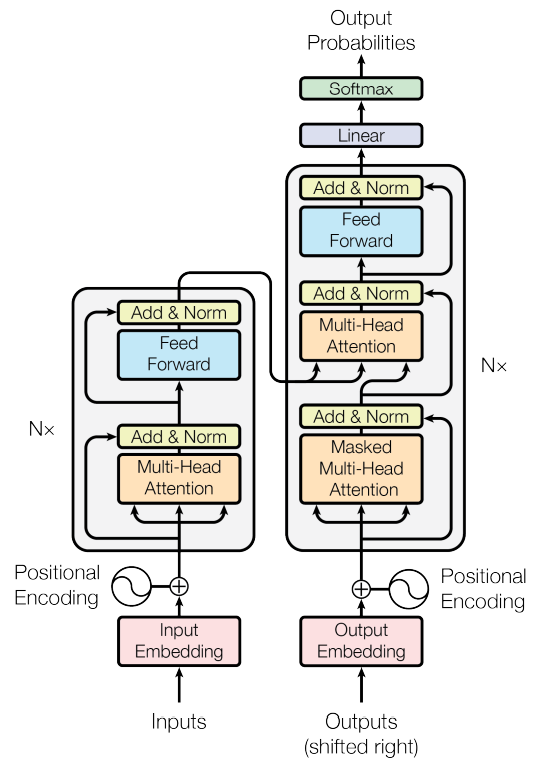
그림 1. 트랜스포머 모델 아키텍쳐 (출처: Vaswani et al., 2017: 3)
초기 자연어 처리 기술은 주로 규칙 기반(Rule-based) 방식을 활용하였습니다. 이 방식은 정규표현식(regular expression) 등을 활용하여 사전에 만들어진 규칙을 바탕으로 자연어를 처리하였습니다. 자연어 처리 기술의 중요한 초석을 놓았지만, 모든 경우의 수를 고려하기 어렵다는 한계가 있었습니다. 이러한 한계를 넘어서기 위해 통계 기반(Statistical-based) 방식이 도입되었고, 딥러닝을 포함한 기계 학습(Machine Learning) 기술이 크게 발전하면서 오늘날 거대언어모델이 상용화되기에 이르렀습니다.
자연어 처리에 대표적으로 사용되는 딥러닝 모델은 순환 신경망(Recurrent Neural Network, RNN)입니다. 순환 신경망은 순방향 신경망(Feedforward Neural Network, FNN)과 달리, 텍스트와 같은 연속형 데이터를 다룰 수 있도록 메모리 셀을 포함하고 있는 구조를 지닙니다. 그러나 기본적인 RNN(’바닐라 RNN’)은 입력 시점(time step)이 길어질수록 이전의 기억이 뒤로 충분히 전달되지 못하는 문제점이 있었습니다. 이를 장기 의존성(Long-Term Dependency) 문제라고 합니다.
이 문제를 보완하기 위해 LSTM(Long Short-Term Memory, 장단기 메모리)(Hochreiter & Schmidhuber, 1997)이 만들어졌습니다. LSTM은 은닉층의 메모리 셀에 입력 게이트, 망각 게이트, 출력 게이트를 추가하여 불필요한 기억은 지우고, 기억해야 할 것들을 확률적으로 결정하게 됩니다. 또한 셀 상태(cell state)가 추가되어 기본적인 RNN과 비교해 조금 더 긴 연속형 자료를 처리할 수 있게 하였습니다. LSTM과 같이 장기 의존성 문제는 해소하면서 LSTM 모델을 좀 더 간소화한 GRU(Gated Recurrent Unit, 게이트 순환 유닛) 모델(Cho et al., 2014)도 있습니다. 통상적으로 순환 신경망은 LSTM이나 GRU 모델을 의미합니다.
기계번역과 같이 서로 길이가 다른 입력과 출력 데이터를 다루기 위해 두 개의 RNN을 연결한 인코더-디코더 구조가 제안되었습니다(Cho et al., 2014; Sutskever et al., 2014). 이를 시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq) 모델이라고 합니다. 인코더는 입력 문장을 받아들여 고정 길이의 벡터 또는 행렬로 변환하고, 디코더는 이 벡터 또는 행렬을 받아들여 다음 단어를 생성하는 방식으로 동작합니다. 그러나 이 모델에서는 제한된 문맥 벡터(context vector)의 크기로 인해 정보 손실 문제가 발생하는 한계가 있습니다. 또한 딥러닝 과정에서 역전파 시에 기울기 값이 급격하게 사라지는 기울기 소실(gradient vanishing) 문제도 남아있게 됩니다.
이러한 문제를 완화하여 입력 시퀀스가 길어지면 출력 시퀀스의 정확도가 떨어지는 것을 보정해주기 위해 어텐션(attention) 메커니즘이 도입되었습니다. 어텐션 메커니즘은 디코더에서 출력 단어를 예측하는 매 시점(time step)마다, 인코더에서의 전체 입력 문장을 다시 한 번 참고하는 것을 의미합니다. 특히 해당 시점에서 예측해야 할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(attention)해서 본다는 의미에서 어텐션 메커니즘이라고 부릅니다. 그 후 기존의 seq2seq 구조인 인코더-디코더를 따르면서도, 어텐션(Attention)만으로 구현한 모델인 트랜스포머(Transformer)가 발표되었습니다. 트랜스포머 모델은 기계번역 등에서 seq2seq 모델을 뛰어넘는 성능을 보여주며 자연어 처리 분야에서 핵심적인 모델로 자리잡게 되었습니다.
트랜스포머의 등장 이후, 다양한 자연어 처리 문제에서 사용되었던 RNN 계열의 신경망인 LSTM, GRU는 트랜스포머로 대체되어가는 추세입니다. 현재 대표적인 거대언어모델인 구글의 BERT(Bidirectional Encoder Representations from Transformers)와 OpenAI의 GPT(Generative Pre-trained Transformer)는 모두 트랜스포머를 기반으로 만들어졌습니다. 다만 BERT는 트랜스포머의 인코더를, GPT는 트랜스포머의 디코더를 활용해 만들어졌다는 차이가 있습니다. BERT와 GPT는 기본적인 모델 구조는 유지하되, 모델의 크기를 키우는 방식으로 상위 버젼이 계속해서 출시되고 있습니다. chatGPT와 같이 자연어 처리 기술이 활용된 거대언어모델이 우리의 삶의 지형을 크게 변화시켜 나가고 있고 새로운 언어모델(LLAMA, Alpaca)도 속속 발표되고 있는 만큼, 앞으로 자연어 처리 기술이 어떻게 더 발전해 나갈지 관심을 가지고 지켜볼 필요가 있을 것 같습니다. 아울러 자연어 처리 기술에 관심있는 분들이라면 트랜스포머를 기반으로 한 자연어 처리 모델과 데이터셋을 제공하는 플랫폼인 허깅페이스(Hugging Face, https://huggingface.co/)를 방문해 보시기를 권합니다. 긴 글 읽어주셔서 감사합니다.
참고자료
Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014a). Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078.
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735-1780. doi:10.1162/neco.1997.9.8.1735.
Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. Advances in neural information processing systems, 27. arXiv:1409.3215. Retrieved from https://arxiv.org/abs/1409.3215.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30. arXiv:1706.03762. Retrieved from https://arxiv.org/abs/1706.03762.
